hvad enhver programmør absolut, positivt har brug for at vide om kodninger og tegnsæt for at arbejde med tekst
Hvis du har at gøre med tekst på en computer, skal du vide om kodninger. Periode. Ja, selvom du bare sender e-mails. Selvom du bare modtager e-mails. Du behøver ikke at forstå hver eneste detalje, men du skal i det mindste vide, hvad hele denne “kodning” ting handler om. Den gode nyhed først: mens emnet kan blive rodet og forvirrende, er grundideen virkelig, virkelig enkel.
denne artikel handler om kodninger og tegnsæt. En artikel af Joel Spolsky med titlen Det absolutte Minimum hver Udvikler absolut, positivt skal vide om Unicode og tegnsæt (ingen undskyldninger!) er en god introduktion til emnet, og jeg nyder meget at læse det en gang imellem. Jeg tøver med at henvise folk til det, der har problemer med at forstå kodningsproblemer, men da det er underholdende, er det ret let på faktiske tekniske detaljer. Jeg håber, at denne artikel kan kaste mere lys over, hvad der præcist er en kodning, og bare hvorfor al din tekst skruer op, når du mindst har brug for det. Denne artikel er rettet mod udviklere (med fokus på PHP), men enhver computerbruger skal kunne drage fordel af det.
få det grundlæggende lige
alle er opmærksomme på dette på et eller andet niveau, men på en eller anden måde synes denne viden pludselig at forsvinde i en diskussion om tekst, så lad os først få det ud: en computer kan ikke gemme “bogstaver”, “tal”, “billeder” eller noget andet. Det eneste, det kan gemme og arbejde med, er bits. En bit kan kun have to værdier: yes eller notrue eller false1 eller 0 eller hvad du ellers vil kalde disse to værdier. Da en computer arbejder med elektricitet, er en “faktisk” bit en blip af elektricitet, der enten er eller ikke er der. For mennesker er dette normalt repræsenteret ved hjælp af 1 og 0 og jeg vil holde fast i denne konvention i hele denne artikel.
for at bruge bits til at repræsentere noget overhovedet udover bits, har vi brug for regler. Vi er nødt til at konvertere en sekvens af bits til noget som bogstaver, tal og billeder ved hjælp af et kodningsskema eller kort kodning. Sådan her:
01100010 01101001 01110100 01110011b i t si denne kodning, 01100010 står for bogstavet “b”, 01101001 for bogstavet “i”, 01110100 står for “t” og 01110011 for “s”. En bestemt sekvens af bits står for et bogstav, og et bogstav står for en bestemt sekvens af bits. Hvis du kan holde dette i dit hoved for 26 bogstaver eller er virkelig hurtige med at se ting op i et bord, kan du læse bits som en bog.
ovenstående kodningsskema er tilfældigvis ASCII. En streng af 1s og 0s er opdelt i dele af otte bit hver (en byte for kort). ASCII-kodningen angiver en tabel, der oversætter bytes til menneskelige læsbare bogstaver. Her er et kort uddrag af denne tabel:
| bits | character |
|---|---|
01000001 |
A |
01000010 |
B |
01000011 |
C |
01000100 |
D |
01000101 |
E |
01000110 |
F |
There are 95 human readable tegn angivet i ASCII-tabellen, inklusive bogstaverne A til Å både med store og små bogstaver, tallene 0 til 9, en håndfuld tegnsætningstegn og tegn som dollarsymbolet, ampersand og et par andre. Det omfatter også 33 værdier for ting som space, line feed, tab, backspace og så videre. Disse kan ikke udskrives i sig selv, men er stadig synlige i en eller anden form og nyttige for mennesker direkte. Et antal værdier er kun nyttige for en computer, f.eks. koder, der angiver starten eller slutningen af en tekst. I alt er der 128 tegn defineret i ASCII-kodningen, hvilket er et dejligt rundt tal (for personer, der beskæftiger sig med computere), da det bruger alle mulige kombinationer af 7 bits (000000000000010000010 gennem 1111111).1
og der har du det, vejen til at repræsentere menneskelig læsbar tekst ved kun at bruge1s og0s.
01001000 01100101 01101100 01101100 01101111 00100000 01010111 01101111 01110010 01101100 01100100“Hej Verden”
vigtige udtryk
for at kode noget i ASCII skal du følge tabellen fra højre til venstre og erstatte bogstaver til bits. For at afkode en streng bits til menneskelige læsbare tegn skal du følge tabellen fra venstre mod højre og erstatte bits med bogstaver.
encode|en lirke/
verb
konverter til en kodet formkode|k lirke /
substantiv
et system med ord, bogstaver, figurer eller andre symboler erstattet af andre ord, bogstaver osv.
at kode betyder at bruge noget til at repræsentere noget andet. En kodning er det sæt regler, hvormed man kan konvertere noget fra en repræsentation til en anden.
andre udtryk, der fortjener afklaring i denne sammenhæng:
tegnsæt, tegnsæt det sæt tegn, der kan kodes. “ASCII-kodningen omfatter et tegnsæt på 128 tegn.”I det væsentlige synonymt med”kodning”. kodeside en” side ” med koder, der kortlægger et tegn til et tal eller en bitsekvens. A. k. A. “bordet”. I det væsentlige synonymt med”kodning”. string en streng er en flok genstande spændt sammen. En bitstreng er en flok bits, som01010011. En tegnstreng er en flok tegn,like this. Synonymt med”sekvens”.
binær, oktal, decimal, sekskant
der er mange måder at skrive tal på. 10011111 i binær er 237 i oktal er 159 i decimal er 9F i seksadecimal. De repræsenterer alle den samme værdi, men geksadecimal er kortere og lettere at læse end binær. Jeg vil holde fast i binær i hele denne artikel for at få punktet bedre og spare læseren et lag af abstraktion. Vær ikke foruroliget over at se tegnkoder, der henvises til i andre notationer andetsteds, det er det samme.
Undskyld-moi?
nu hvor vi ved, hvad vi taler om, lad os bare sige det: 95 tegn er virkelig ikke meget, når det kommer til sprog. Det dækker det grundlæggende i engelsk, men hvad med at skrive et farligt brev på fransk? På tysk? En invitation til en SM lrrg lrsbord på svensk? Ikke i ASCII. Der er ingen specifikation på, hvordan at repræsentere nogen af de breve, é, ß ü, ä, ö, eller å i ASCII, så du ikke kan bruge dem.
“men se på det,” sagde europæerne, “i en fælles computer med 8 bit til byte spilder ASCII en hel bit, som altid er indstillet til0! Vi kan bruge den bit til at presse en hel ‘nother 128 værdier ind i den tabel!”Og det gjorde de også. Men alligevel er der mere end 128 måder at stryge, skære, skråstreg og prikke en vokal på. Ikke alle variationer af bogstaver og krusninger, der bruges på alle europæiske sprog, kan repræsenteres i den samme tabel med maksimalt 256 værdier. Så hvad verden endte med er et væld af kodningsordninger, standarder, de facto standarder og halvstandarder, der alle dækker en anden delmængde af tegn. Nogen havde brug for at skrive et dokument om svensk på tjekkisk, fandt ud af, at ingen kodning dækkede begge sprog og opfandt et. Eller så kan jeg forestille mig, at det gik utallige gange.
og ikke at glemme russisk, Hindi, arabisk, hebraisk, koreansk og alle de andre sprog, der i øjeblikket er i aktiv brug på denne planet. For ikke at nævne dem, der ikke længere er i brug. Når du har løst problemet med, hvordan du skriver blandede sprogdokumenter på alle disse sprog, kan du prøve dig selv på kinesisk. Eller Japansk. Begge indeholder titusinder af tegn. Du har 256 mulige værdier til en byte bestående af 8 bit. Gå!
multi-byte-kodninger
for at oprette en tabel, der kortlægger tegn til bogstaver for et sprog, der bruger mere end 256 tegn, er en byte simpelthen ikke nok. Ved hjælp af to bytes (16 bit) er det muligt at kode 65.536 forskellige værdier. BIG-5 er sådan en dobbelt-byte kodning. I stedet for at bryde en streng af bits i blokke af otte, bryder den den i blokke af 16 og har en stor (jeg mener stor) tabel, der angiver hvilket tegn hver kombination af bits kort til. BIG – 5 i sin grundlæggende form dækker for det meste traditionelle kinesiske tegn. GB18030 er en anden kodning, der i det væsentlige gør det samme, men inkluderer både traditionelle og forenklede kinesiske tegn. Og før du spørger, ja, der er kodninger, der kun dækker forenklet kinesisk. Kan ikke bare have en kodning nu, kan vi?
her et lille uddrag fra GB18030 bordet:
| bits | character |
|---|---|
10000001 01000000 |
丂 |
10000001 01000001 |
丄 |
10000001 01000010 |
丅 |
10000001 01000011 |
丆 |
10000001 01000100 |
丏 |
GB18030 covers quite a range of characters (including a large part of latin tegn), men i sidste ende er endnu et specialiseret kodningsformat blandt mange.
Unicode til forvirringen

endelig havde nogen nok af rodet og satte sig for at smede en ring for at binde dem alle oprette en kodning standard for at forene alle kodningsstandarder. Denne standard er Unicode. Det definerer dybest set et ginormt bord med 1.114.112 kodepunkter, der kan bruges til alle slags bogstaver og symboler. Det er masser at kode alle europæiske, mellemøstlige, Fjernøstlige, sydlige, nordlige, vestlige, præhistorikere og fremtidige tegn menneskeheden kender til.2 ved hjælp af Unicode kan du skrive et dokument, der indeholder stort set ethvert sprog ved hjælp af ethvert tegn, du kan skrive på en computer. Dette var enten umuligt eller meget meget svært at få lige før Unicode kom sammen. Der er endda en uofficiel sektion for Klingon i Unicode. Faktisk er Unicode stor nok til at give mulighed for uofficielle områder til privat brug.
så hvor mange bits bruger Unicode til at kode alle disse tegn? Ingen. Fordi Unicode ikke er en kodning.
forvirret? Mange mennesker synes at være. Unicode definerer først og fremmest en tabel med kodepunkter for tegn. Det er en fancy måde at sige “65 står for a, 66 står for B og 9.731 står for Kristus” (Seriøst, det gør det). Hvordan disse kodepunkter faktisk kodes i bits er et andet emne. For at repræsentere 1.114.112 forskellige værdier er to bytes ikke nok. Tre bytes er, men tre bytes er ofte akavet at arbejde med, så fire bytes ville være det behagelige minimum. Men medmindre du rent faktisk bruger kinesisk eller nogle af de andre tegn med store tal, der tager mange bits at kode, vil du aldrig bruge en stor del af disse fire bytes. Hvis bogstavet “A”altid blev kodet til 00000000 00000000 00000000 01000001,” B”altid til 00000000 00000000 00000000 01000010 og så videre, ville ethvert dokument oppustes til fire gange den nødvendige størrelse.
for at optimere dette er der flere måder at kode Unicode-kodepunkter i bits. UTF-32 er en sådan kodning, der koder for alle Unicode-kodepunkter ved hjælp af 32 bit. Det vil sige fire bytes pr. Det er meget enkelt, men spilder ofte meget plads. UTF-16 og UTF-8 er kodninger med variabel længde. Hvis et tegn kan repræsenteres ved hjælp af en enkelt byte (fordi dens kodepunkt er et meget lille tal), vil UTF-8 kode det med en enkelt byte. Hvis det kræver to bytes, vil det bruge to bytes og så videre. Det har detaljerede måder at bruge de højeste bits i en byte til at signalere, hvor mange bytes et tegn består af. Dette kan spare plads, men kan også spilde plads, hvis disse signalbits skal bruges ofte. UTF-16 er i midten ved hjælp af mindst to bytes og vokser til op til fire bytes efter behov.
| character | encoding | bits |
|---|---|---|
| A | UTF-8 | 01000001 |
| A | UTF-16 | 00000000 01000001 |
| A | UTF-32 | 00000000 00000000 00000000 01000001 |
| あ | UTF-8 | 11100011 10000001 10000010 |
| あ | UTF-16 | 00110000 01000010 |
| あ | UTF-32 | 00000000 00000000 00110000 01000010 |
og det er alt der er til det. Unicode er et stort bord, der kortlægger tegn til tal, og de forskellige UTF-kodninger angiver, hvordan disse tal er kodet som bits. Samlet set er Unicode endnu et kodningsskema. Der er ikke noget særligt ved det, det prøver bare at dække alt, mens det stadig er effektivt. Og det er en god ting.
kodepunkter
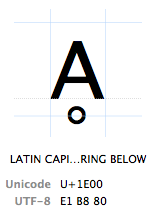
tegn henvises til ved deres “Unicode-kodepunkt”. Unicode-kodepunkter er skrevet i geksadecimal (for at holde tallene kortere), forud for et “U+” (det er bare hvad de gør, det har ingen anden betydning end “dette er et Unicode-kodepunkt”). Det tegn, der har et Unicode-kodepunkt, er U+1e00. I andre (decimal) ord er det den 7680. karakter af Unicode-tabellen. Det kaldes officielt”LATIN stort bogstav A med RING nedenfor”.
TL;DR
en oversigt over alt det ovenstående: ethvert tegn kan kodes i mange forskellige bitsekvenser, og enhver bestemt bitsekvens kan repræsentere mange forskellige tegn, afhængigt af hvilken kodning der bruges til at læse eller skrive dem. Årsagen er simpelthen fordi forskellige kodninger bruger forskellige antal bits pr.
| bits | encoding | characters |
|---|---|---|
11000100 01000010 |
Windows Latin 1 | ÄB |
11000100 01000010 |
Mac Roman | ƒB |
11000100 01000010 |
GB18030 | 腂 |
| characters | encoding | bits |
|---|---|---|
| f list | vinduer Latin 1 | 01000110 11111000 11110110 |
| f list | Mac roman |
01000110 10111111 10011010 |
| f ret | UTF-8 |
01000110 11000011 10111000 11000011 10110110 |
misforståelser, forvirringer og problemer
når det er sagt, kommer vi til de faktiske problemer, som mange brugere og programmører oplever hver dag, hvordan disse problemer vedrører alle ovenstående og hvad deres løsning er. Det største problem af alle er:
hvorfor i Guds navn er mine Tegn forvrænget?!
ÉGÉìÉRÅ;Hvis det$string var i en enkelt byte-kodning, ville dette give os det første tegn. Men kun fordi” karakter “falder sammen med” byte ” i en enkelt-byte-kodning. PHP giver os simpelthen den første byte uden at tænke på “tegn”. Strenge er byte sekvenser til PHP, intet mere, intet mindre. Alle disse” læsbare karakter ” ting er en menneskelig ting, og PHP er ligeglad med det.
01000100 01101111 01101110 00100111 01110100D o n ' t01100011 01100001 01110010 01100101 00100001c a r e !det samme gælder for mange standardfunktioner somsubstrstrpostrim og så videre. Den ikke-støtte opstår, hvis der er en uoverensstemmelse mellem længden af en byte og et tegn.
11100110 10111100 10100010 11100101 10101101 10010111漢 字
brug af $string på ovenstående streng vil igen give os den første byte, som er 11100110. Med andre ord, en tredjedel af den tre-byte karakter “Krist”. 11100110 er i sig selv en ugyldig UTF-8-sekvens, så strengen er nu brudt. Hvis du havde lyst til det, kunne du prøve at fortolke det i en anden kodning, hvor 11100110 repræsenterer et gyldigt tegn, hvilket vil resultere i et tilfældigt tegn. Hav det sjovt, men brug det ikke i produktionen.
og det er faktisk alt, hvad der er til det. “PHP understøtter ikke Unicode” betyder simpelthen, at de fleste PHP-funktioner antager en byte = et tegn, hvilket kan føre til, at det hugger multi-byte-tegn i halvdelen eller beregner længden af strenge forkert, hvis du naivt bruger ikke-multi-byte-Opmærksomme funktioner på multi-byte-strenge. Det betyder ikke, at du ikke kan bruge Unicode i PHP, eller at hver Unicode-streng skal velsignes af utf8_encode eller anden sådan vrøvl.
heldigvis er der multibyte-Strengforlængelsen, som replikerer alle vigtige strengfunktioner på en multi-byte bevidst måde. Brug af mb_substr($string, 0, 1, 'UTF-8')på ovenstående streng returnerer korrekt 11100110 10111100 10100010, som er hele “venstre” – tegnet. Fordimb_ funktionerne nu skal tænke på, hvad de laver, skal de vide, hvilken kodning de arbejder på. Derfor accepterer hver mb_ funktion en $encoding parameter også. Alternativt kan dette indstilles globalt for alle mb_ funktioner ved hjælp af mb_internal_encoding.
brug og misbrug af PHP ‘s håndtering af kodninger
hele spørgsmålet om PHP’ s (ikke-)support til Unicode er, at det bare er ligeglad. Strenge er byte sekvenser til PHP. Hvilke bytes i særdeleshed betyder ikke noget. PHP gør ikke noget med strenge undtagen at holde dem gemt i hukommelsen. PHP har simpelthen ikke noget begreb om enten tegn eller kodninger. Og medmindre det forsøger at manipulere strenge, behøver det heller ikke; det holder bare på bytes, der måske eller måske ikke i sidste ende fortolkes som tegn af en anden. Det eneste krav PHP har af kodninger er, at PHP kildekode skal gemmes i en ASCII kompatibel kodning. PHP-parseren leder efter bestemte tegn, der fortæller det, hvad de skal gøre. $00100100) signalerer starten af en variabel, =00111101) en opgave, "00100010) starten og slutningen af en streng og så videre. Alt andet, der ikke har nogen særlig betydning for parseren, tages bare som en bogstavelig bytesekvens. Det inkluderer alt mellem citater, som diskuteret ovenfor. Dette betyder følgende:
-
Du kan ikke gemme PHP-kildekoden i en ASCII-inkompatibel kodning. For eksempel i UTF-16 a
"er kodet som00000000 00100010. Til PHP, som forsøger at læse alt som ASCII, er det enNULbyte efterfulgt af en".PHP vil sandsynligvis få en hik, hvis hver anden karakter den Finder er enNULbyte. -
Du kan gemme PHP kildekode i enhver ASCII-kompatibel kodning. Hvis de første 128 kodepunkter i en kodning eridentisk til ASCII, kan PHP analysere det. Alle tegn, der på nogen måde er vigtige for PHP, er inden for de 128 kodepunkter, der er defineret af ASCII. Hvis strenglitteraler indeholder kodepunkter ud over det, er PHP ligeglad. Du kan gemme PHP-kildekode i ISO-8859-1, Mac Roman, UTF-8 eller enhver anden ASCII-kompatibel kodning. String literals i dit script vilhar uanset kodning du gemte din kildekode som.
-
enhver ekstern fil, du behandler med PHP, kan være i den kodning, du kan lide. Hvis PHP ikke behøver at analysere det, er der ingen krav til at opfylde for at holde PHP-parseren glad.
$foo = file_get_contents('bar.txt');ovenstående vil simpelthen læse bitene i
bar.txti variablen$foo. PHP forsøger ikke at fortolke,konvertere, kode eller på anden måde fikle med indholdet. Filen kan endda indeholde binære data såsom et billede,PHP er ligeglad. -
Hvis interne og eksterne kodninger skal matche, skal de matche. En almindelig sag er lokalisering, hvorkildekoden indeholder noget som
echo localize('Foobar')og en ekstern lokaliseringsfil indeholdernoget i retning af dette:msgid "Foobar"msgstr "フーバー"begge” Foobar ” – strenge skal have en identisk bitrepræsentation, hvis du vil finde den korrekte lokalisering.Hvis kildekoden blev gemt i ASCII, men lokaliseringsfilen i UTF-16, ville strengene ikke matche.Enten ville en slags kodningskonvertering være nødvendig eller brugen af en kodningsbevidst strengtilpasningsfunktion.
den kloge læser kan spørge på dette tidspunkt, om det er muligt at gemme en UTF-16 byte-sekvens inde i en streng bogstavelig af en ASCII-kodet kildekodefil, som svaret ville være: absolut.
echo "UTF-16";Hvis du kan medbringe din teksteditor for at gemmeecho "og";dele i ASCII og kunUTF-16 i UTF-16 fungerer dette fint. Den nødvendige binære repræsentation for det ser sådan ud:
01100101 01100011 01101000 01101111 00100000 00100010e c h o "11111110 11111111 00000000 01010101 00000000 01010100(UTF-16 marker) U T00000000 01000110 00000000 00101101 00000000 00110001F - 100000000 00110110 00100010 001110116 " ; den første linje og de sidste to byte er ASCII. Resten er UTF-16 med to bytes pr. Den førende 11111110 11111111 på linje 2 er en markør, der kræves i starten af UTF-16-kodet tekst (krævet af UTF-16-standarden, PHP giver ikke noget forbandet). Dette PHP-script udsender med glæde strengen ” UTF-16 “kodet i UTF-16, fordi det simpelt udsender bytes mellem de to dobbelt citater, som tilfældigvis repræsenterer teksten” UTF-16 ” kodet i UTF-16. Kildekodefilen er dog hverken helt gyldig ASCII eller UTF-16, så det vil ikke være meget sjovt at arbejde med den i en teksteditor.
Bottom line
PHP understøtter Unicode, eller faktisk enhver kodning, helt fint, så længe visse krav er opfyldt for at holde parseren glad, og programmøren ved, hvad han laver. Du behøver virkelig kun at være forsigtig, når du manipulerer strenge, som inkluderer udskæring, trimning, tælling og andre operationer, der skal ske på et tegnniveau snarere end et byte-niveau. Hvis du ikke” gør noget “med dine strenge udover at læse og udsende dem, vil du næppe have problemer med PHP’ s støtte til kodninger, som du ikke ville have på noget andet sprog også.
Kodningsbevidste sprog
Hvad betyder det for et sprog at understøtte Unicode da? Javascript understøtter for eksempel Unicode. Faktisk er enhver streng i Javascript UTF-16 kodet. Faktisk er det det eneste Javascript beskæftiger sig med. Du kan ikke have en streng i Javascript, der ikke er UTF-16 kodet. Javascript tilbeder Unicode i det omfang, at der ikke er nogen mulighed for at håndtere nogen anden kodning på kernesproget. Da Javascript oftest køres i en bro.ser, er det ikke et problem, da bro. sereren kan håndtere den verdslige logistik ved kodning og afkodning af input og output.
andre sprog er simpelthen kodende Opmærksomme. Internt gemmer de strenge i en bestemt kodning, ofte UTF-16. Til gengæld skal de fortælles eller forsøge at opdage kodningen af alt, hvad der har at gøre med tekst. De har brug for at vide, hvilken kodning kildekoden er gemt i, hvilken kodning en fil, de skal læse, er i, hvilken kodning du vil udsende tekst i; og de konverterer kodninger på farten efter behov med en vis manifestation af Unicode som mellemmand. De gør det samme, Du kan/bør/skal gøre i PHP semi-automatisk bag kulisserne. Det er hverken bedre eller værre end PHP, bare anderledes. Det gode ved det er, at standardsprogfunktioner, der beskæftiger sig med strenge, bare fungerer prist, mens man i PHP er nødt til at spare lidt opmærksomhed på, om en streng kan indeholde multi-byte-tegn eller ej, og vælg strengmanipulationsfunktioner i overensstemmelse hermed.
dybden af Unicode
da Unicode beskæftiger sig med mange forskellige scripts og mange forskellige problemer, har den meget dybde til det. For eksempel indeholder Unicode-standarden oplysninger om sådanne problemer som CJK ideograph unification. Det betyder information om, at to eller flere kinesiske/japanske/koreanske tegn faktisk repræsenterer den samme karakter i lidt forskellige skrivemetoder. Eller regler om konvertering fra små bogstaver til store bogstaver, omvendt og rundtur, hvilket ikke altid er så ligetil i alle scripts som det er i de fleste vesteuropæiske latinske afledte scripts. Nogle tegn kan også repræsenteres ved hjælp af forskellige kodepunkter. Bogstavet “Kris”kan for eksempel repræsenteres ved hjælp af kodepunktet U+00f6 (“LATIN lille bogstav O med DIAERESIS”) eller som de to kodepunkter U+006f (“LATIN lille bogstav O”) og U+0308 (“kombination af DIAERESIS”), det vil sige bogstavet” o “kombineret med””. I UTF-8 er det enten dobbeltbytesekvensen 11000011 10110110eller tre-byte-sekvensen01101111 11001100 10001000, begge repræsenterer den samme menneskelige læsbare karakter. Som sådan er der regler for normalisering inden for Unicode-standarden, dvs.hvordan en af disse former kan konverteres til den anden. Dette og meget mere er uden for denne artikels anvendelsesområde, men man bør være opmærksom på det.
endelig TL;DR
- tekst er altid en sekvens af bits, der skal oversættes til menneskelig læsbar tekst ved hjælp af opslagstabeller. Hvis den forkerte opslagstabel bruges, bruges det forkerte tegn.
- du har faktisk aldrig direkte at gøre med “tegn” eller “tekst”, du har altid at gøre med bits set gennem flere lag af abstraktioner. Forkerte resultater er et tegn på, at et af abstraktionslagene fejler.
- hvis to systemer taler med hinanden, skal de altid angive, hvilken kodning de vil tale med hinanden i. Det enkleste eksempel på dette er denne hjemmeside, der fortæller din bro.ser, at den er kodet i UTF-8.
- i denne dag og alder er standardkodningen UTF-8, da den kan kode stort set enhver karakter af interesse, er bagudkompatibel med de-facto baseline ASCII og er relativt pladseffektiv for de fleste brugssager alligevel.
- andre kodninger har stadig lejlighedsvis deres anvendelser, men du bør have en konkret grund til at ville håndtere hovedpine forbundet med tegnsæt, der kun kan kode en delmængde af Unicode.
- dagene for en byte = et tegn er forbi, og både programmører og programmer skal indhente dette.
nu skal du virkelig ikke have nogen undskyldning mere næste gang du garble noget tekst.
-
Ja, det betyder, at ASCII kan gemmes og overføres ved hjælp af kun 7 bits, og det er det ofte. Nej, Dette er ikke inden for rammerne af denne artikel, og af hensyn til argumentet antager vi, at den højeste bit er “spildt” i ASCII.
-
og hvis det ikke er, vil det blive udvidet. Det har allerede været flere gange. Bemærk venligst, at når jeg bruger udtrykket “start” sammen med “byte”, mener jeg det fra det menneskelige læsbare synspunkt. læs UTF-8-specifikationen, hvis du vil følge dette med pen og papir.
-
Hej, Jeg er en programmør, ikke en biolog.
-
og selvfølgelig vil der ikke være nogen nylig backup. et “Unicode-tegn” er et kodepunkt i Unicode-tabellen. “Kris” er ikke en Unicode-karakter, det er Hiragana-brevet Kris. Der er et Unicode-kodepunkt for det, men det gør ikke selve brevet til et Unicode-tegn. Et “UTF-8-tegn” er et oksymoron, men kan strækkes til at betyde, hvad der teknisk kaldes en “UTF-8-sekvens”, som er en byte-sekvens på en, to, tre eller fire bytes, der repræsenterer et Unicode-tegn. Begge udtryk bruges ofte i betydningen “ethvert bogstav, der ikke er en del af mit tastatur”, hvilket betyder absolut ingenting.
-
http://www.php.net/manual/en/function.utf8-encode.php Lira
om forfatteren
David C. Sentgraf er en internetudvikler, der arbejder delvist i Japan og Europa og isa regelmæssigt på stakoverløb.Hvis du har feedback, kritik eller tilføjelser, er du velkommen til at prøve