Lo que todo programador necesita saber absoluta y positivamente sobre codificaciones y conjuntos de caracteres para trabajar con texto
Si está tratando con texto en una computadora, necesita saber sobre codificaciones. Periodo. Sí, incluso si solo está enviando correos electrónicos. Incluso si solo está recibiendo correos electrónicos. No necesitas entender hasta el último detalle, pero al menos debes saber de qué se trata todo este asunto de la «codificación». Y las buenas noticias primero: si bien el tema puede ser desordenado y confuso, la idea básica es muy, muy simple.
Este artículo trata sobre codificaciones y conjuntos de caracteres. Un artículo de Joel Spolsky titulado El Mínimo Absoluto Que Todo Desarrollador de Software Debe Saber Absoluta y Positivamente Sobre Unicode y Conjuntos de Caracteres (¡Sin Excusas!) es una buena introducción al tema y disfruto mucho leerlo de vez en cuando. Sin embargo, dudo en referir a personas que tienen problemas para comprender los problemas de codificación, ya que, aunque es entretenido, es bastante liviano en los detalles técnicos reales. Espero que este artículo pueda arrojar algo más de luz sobre qué es exactamente una codificación y por qué todo tu texto se arruina cuando menos lo necesitas. Este artículo está dirigido a desarrolladores (con un enfoque en PHP), pero cualquier usuario de computadora debería poder beneficiarse de él.
Aclarar los conceptos básicos
Todo el mundo es consciente de esto en algún nivel, pero de alguna manera este conocimiento parece desaparecer repentinamente en una discusión sobre texto, así que vamos a sacarlo primero: Una computadora no puede almacenar «letras», «números», «imágenes» o cualquier otra cosa. Lo único con lo que puede almacenar y trabajar son bits. Un bit sólo puede tener dos valores: yes o notrue o false1 o 0 o cualquier otra cosa que usted desea llamar a estos dos valores. Dado que una computadora funciona con electricidad, un bit «real» es un blip de electricidad que está o no está ahí. Para los humanos, esto generalmente se representa usando 1 y 0 y me quedaré con esta convención a lo largo de este artículo.
Para usar bits para representar cualquier cosa que no sea bits, necesitamos reglas. Necesitamos convertir una secuencia de bits en algo como letras, números e imágenes usando un esquema de codificación, o codificación para abreviar. Como esto:
01100010 01101001 01110100 01110011b i t sEn este tipo de codificación, 01100010 representa la letra «b», 01101001 por la letra «i», 01110100 significa «t» y 01110011 «s». Una cierta secuencia de bits representa una letra y una letra representa una cierta secuencia de bits. Si puedes mantener esto en tu cabeza por 26 letras o eres muy rápido buscando cosas en una mesa, podrías leer bits como un libro.
El esquema de codificación anterior resulta ser ASCII. Una cadena de 1 s y 0 s se divide en partes de ocho bits cada una (un byte para abreviar). La codificación ASCII especifica una tabla que traduce bytes a letras legibles por humanos. Aquí hay un breve fragmento de esa tabla:
| bits | character |
|---|---|
01000001 |
A |
01000010 |
B |
01000011 |
C |
01000100 |
D |
01000101 |
E |
01000110 |
F |
There are 95 human readable caracteres especificados en la tabla ASCII, incluidas las letras de la A a la Z en mayúsculas y minúsculas, los números del 0 al 9, un puñado de signos de puntuación y caracteres como el símbolo del dólar, el ampersand y algunos otros. También incluye 33 valores para cosas como espacio, alimentación de línea, tabulación, retroceso, etc. Estos no son imprimibles per se, pero aún son visibles de alguna forma y útiles para los humanos directamente. Una serie de valores solo son útiles para una computadora, como códigos para significar el inicio o el final de un texto. En total hay 128 caracteres definidos en la codificación ASCII, que es un buen número redondo (para personas que trabajan con computadoras), ya que utiliza todas las combinaciones posibles de 7 bits (000000000000010000010 hasta 1111111).1
Y ahí lo tienes, la forma de representar texto legible por humanos usando solo 1s y 0s.
01001000 01100101 01101100 01101100 01101111 00100000 01010111 01101111 01110010 01101100 01100100«Hola Mundo»
términos Importantes
Para codificar algo en ASCII, siga la tabla de derecha a izquierda, sustituyendo las letras de bits. Para decodificar una cadena de bits en caracteres legibles por humanos, siga la tabla de izquierda a derecha, sustituyendo las letras por bits.
codificar |enˈkōd|
verbo
convertir en una forma codificadacode / kōd /
sustantivo
un sistema de palabras, letras, figuras u otros símbolos sustituidos por otras palabras, letras, etc.
Codificar significa usar algo para representar otra cosa. Una codificación es el conjunto de reglas con las que se puede convertir algo de una representación a otra.
Otros términos que merecen una aclaración en este contexto:
conjunto de caracteres, conjunto de caracteres El conjunto de caracteres que se pueden codificar. «La codificación ASCII abarca un conjunto de caracteres de 128 caracteres.»Esencialmente sinónimo de «codificación». página de códigos Una «página» de códigos que asigna un carácter a un número o secuencia de bits. También conocido como «la mesa». Esencialmente sinónimo de «codificación». cuerda Una cuerda es un montón de objetos ensartados. Una cadena de bits es un montón de bits, como
01010011. Una cadena de caracteres es un grupo de caracteres,like this. Sinónimo de «secuencia».
Binario, octal, decimal, hexadecimal
Hay muchas formas de escribir números. 10011111 en binario es 237 en octal es 159 en decimal es 9F en hexadecimal. Todos ellos representan el mismo valor, pero hexadecimal es más corto y más fácil de leer que binario. Me quedaré con binario a lo largo de este artículo para transmitir mejor el punto y ahorrarle al lector una capa de abstracción. No se alarme al ver códigos de caracteres mencionados en otras anotaciones en otros lugares, es todo lo mismo.
¿Excusez-moi?
Ahora que sabemos de lo que estamos hablando, digamos que 95 caracteres realmente no es mucho cuando se trata de idiomas. Cubre los conceptos básicos del inglés, pero ¿qué hay de escribir una carta atrevida en francés? A Straßenübergangsänderungsgesetz en alemán? Una invitación a un smörgåsbord en sueco? Bueno, no podrías, no en ASCII. No hay ninguna especificación sobre cómo representar cualquiera de las letras é, ß, ü, ä, ö o å en ASCII, por lo que no puede usarlas.
«Pero míralo», dijeron los europeos,»en una computadora común con 8 bits por byte, ASCII está desperdiciando un bit completo que siempre se establece en 0! ¡Podemos usar ese bit para comprimir un total de 128 valores en esa tabla!»Y así lo hicieron. Pero aún así, hay más de 128 formas de trazo, corte, barra y el punto de una vocal. No todas las variaciones de letras y garabatos utilizadas en todas las lenguas europeas pueden representarse en la misma tabla con un máximo de 256 valores. Así que el mundo terminó con una gran cantidad de esquemas de codificación, estándares, estándares de facto y estándares a medias que cubren un subconjunto diferente de caracteres. Alguien necesitaba escribir un documento sobre sueco en checo, descubrió que ninguna codificación cubría ambos idiomas e inventó uno. O eso imagino que pasó incontables veces.
Y sin olvidar el ruso, el Hindi, el Árabe, el Hebreo, el Coreano y todos los demás idiomas que se usan actualmente en este planeta. Sin mencionar los que ya no se usan. Una vez que haya resuelto el problema de cómo escribir documentos en idiomas mixtos en todos estos idiomas, pruebe con el chino. O japonés. Ambos contienen decenas de miles de caracteres. Tiene 256 valores posibles para un byte que consta de 8 bits. ¡Vamos!
Codificaciones de varios bytes
Para crear una tabla que asigne caracteres a letras para un idioma que use más de 256 caracteres, un byte simplemente no es suficiente. Usando dos bytes (16 bits), es posible codificar 65.536 valores distintos. BIG-5 es una codificación de doble byte. En lugar de dividir una cadena de bits en bloques de ocho, la divide en bloques de 16 y tiene una tabla grande (quiero decir, GRANDE) que especifica a qué carácter se asigna cada combinación de bits. BIG-5 en su forma básica cubre principalmente caracteres chinos tradicionales. GB18030 es otra codificación que esencialmente hace lo mismo, pero incluye caracteres chinos tradicionales y simplificados. Y antes de preguntar, sí, hay codificaciones que solo cubren el chino simplificado. No podemos tener una codificación, ¿verdad?
Aquí un pequeño extracto de la tabla GB18030:
| bits | character |
|---|---|
10000001 01000000 |
丂 |
10000001 01000001 |
丄 |
10000001 01000010 |
丅 |
10000001 01000011 |
丆 |
10000001 01000100 |
丏 |
GB18030 covers quite a range of characters (including a large part of latin caracteres), pero al final es otro formato de codificación especializado entre muchos.
Unicode a la confusión

Finalmente alguien tuvo suficiente del lío y se dispuso a forjar un anillo para vincularlos a todos, crear una codificación estándar para unificar todos los estándares de codificación. Este estándar es Unicode. Básicamente define una enorme tabla de 1.114.112 puntos de código que se pueden usar para todo tipo de letras y símbolos. Eso es suficiente para codificar a todos los personajes europeos, del Medio Oriente, del Lejano Oriente, del Sur, del Norte, del Oeste, prehistóricos y futuros que la humanidad conoce.2 Con Unicode, puede escribir un documento que contenga prácticamente cualquier idioma utilizando cualquier carácter que pueda escribir en una computadora. Esto era imposible o muy, muy difícil de conseguir antes de que llegara Unicode. Incluso hay una sección no oficial para Klingon en Unicode. De hecho, Unicode es lo suficientemente grande como para permitir áreas no oficiales de uso privado.
Entonces, ¿cuántos bits utiliza Unicode para codificar todos estos caracteres? Ninguno. Porque Unicode no es una codificación.
Confundido? Mucha gente parece serlo. Unicode define en primer lugar una tabla de puntos de código para caracteres. Esa es una forma elegante de decir «65 significa A, 66 significa B y 9,731 significa ☃» (en serio, lo hace). La forma en que estos puntos de código se codifican en bits es un tema diferente. Para representar 1.114.112 valores diferentes, dos bytes no son suficientes. Tres bytes lo son, pero tres bytes a menudo son difíciles de trabajar, por lo que cuatro bytes serían el mínimo cómodo. Pero, a menos que realmente estés usando chino o algunos de los otros caracteres con números grandes que requieren muchos bits para codificar, nunca usarás una gran parte de esos cuatro bytes. Si la letra «A» siempre estaba codificada en 00000000 00000000 00000000 01000001, » B «siempre en 00000000 00000000 00000000 01000010 y así sucesivamente, cualquier documento se hincharía hasta cuatro veces el tamaño necesario.
Para optimizar esto, hay varias formas de codificar puntos de código Unicode en bits. UTF – 32 es una codificación que codifica todos los puntos de código Unicode utilizando 32 bits. Es decir, cuatro bytes por carácter. Es muy simple, pero a menudo desperdicia mucho espacio. UTF-16 y UTF-8 son codificaciones de longitud variable. Si un carácter se puede representar usando un solo byte (porque su punto de código es un número muy pequeño), UTF-8 lo codificará con un solo byte. Si requiere dos bytes, utilizará dos bytes y así sucesivamente. Tiene formas elaboradas de usar los bits más altos de un byte para indicar cuántos bytes contiene un carácter. Esto puede ahorrar espacio, pero también puede desperdiciar espacio si estos bits de señal deben usarse con frecuencia. UTF-16 está en el medio, usando al menos dos bytes, creciendo hasta cuatro bytes según sea necesario.
| character | encoding | bits |
|---|---|---|
| A | UTF-8 | 01000001 |
| A | UTF-16 | 00000000 01000001 |
| A | UTF-32 | 00000000 00000000 00000000 01000001 |
| あ | UTF-8 | 11100011 10000001 10000010 |
| あ | UTF-16 | 00110000 01000010 |
| あ | UTF-32 | 00000000 00000000 00110000 01000010 |
Y eso es todo allí está a él. Unicode es una tabla grande que asigna caracteres a números y las diferentes codificaciones UTF especifican cómo se codifican estos números como bits. En general, Unicode es otro esquema de codificación. No tiene nada de especial, solo trata de cubrir todo sin dejar de ser eficiente. Y Eso Es Algo Bueno.™
Puntos de código
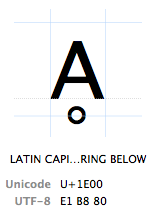
Los caracteres se refieren por su»punto de código Unicode». Los puntos de código Unicode se escriben en hexadecimal (para mantener los números más cortos), precedidos por una «U+» (eso es justo lo que hacen, no tiene otro significado que «este es un punto de código Unicode»). El carácter Ḁ tiene el punto de código Unicode U + 1E00. En otras palabras (decimales), es el carácter 7680 de la tabla Unicode. Se llama oficialmente «LETRA A MAYÚSCULA LATINA CON ANILLO DEBAJO».
TL; DR
Un resumen de todo lo anterior: Cualquier carácter puede codificarse en muchas secuencias de bits diferentes y cualquier secuencia de bits en particular puede representar muchos caracteres diferentes, dependiendo de la codificación que se use para leerlos o escribirlos. La razón es simplemente porque diferentes codificaciones usan diferentes números de bits por caracteres y diferentes valores para representar diferentes caracteres.
| bits | encoding | characters |
|---|---|---|
11000100 01000010 |
Windows Latin 1 | ÄB |
11000100 01000010 |
Mac Roman | ƒB |
11000100 01000010 |
GB18030 | 腂 |
| characters | encoding | bits |
|---|---|---|
| Føö | Windows latina 1 | 01000110 11111000 11110110 |
| Føö | Mac Romano | 01000110 10111111 10011010 |
| Føö | UTF-8 | 01000110 11000011 10111000 11000011 10110110 |
Malentendidos, confusiones y problemas
Habiendo dicho todo eso, llegamos a la actual de los problemas experimentados por muchos usuarios y programadores de cada día, cómo los problemas se refieren a todo lo anterior, y cuál es su solución. El mayor problema de todos es:
¿Por qué, en nombre de Dios, mis personajes son confusos?!
ÉGÉìÉRÅ; Si ese $string estaba en una codificación de un solo byte, esto nos daría el primer carácter. Pero solo porque» carácter «coincide con» byte » en una codificación de un solo byte. PHP simplemente nos da el primer byte sin pensar en «caracteres». Las cadenas son secuencias de bytes a PHP, nada más, nada menos. Todo este «carácter legible» es una cosa humana y a PHP no le importa.
01000100 01101111 01101110 00100111 01110100D o n ' t01100011 01100001 01110010 01100101 00100001c a r e !lo mismo pasa con muchas funciones estándar tales como substrstrpostrim y así sucesivamente. La falta de soporte surge si hay una discrepancia entre la longitud de un byte y un carácter.
11100110 10111100 10100010 11100101 10101101 10010111漢 字
Usando $string en la cadena anterior será, de nuevo, nos dan el primer byte, que es 11100110. En otras palabras, un tercio del carácter de tres bytes «漢». 11100110 es, por sí mismo, una secuencia UTF-8 no válida, por lo que la cadena ahora está rota. Si lo desea, puede intentar interpretarlo en otra codificación donde 11100110 representa un carácter válido, lo que dará lugar a un carácter aleatorio. Diviértete, pero no lo uses en producción.
Y eso es todo lo que hay que hacer. «PHP no admite Unicode de forma nativa» simplemente significa que la mayoría de las funciones de PHP asumen un byte = un carácter, lo que puede llevar a cortar caracteres de varios bytes por la mitad o calcular la longitud de las cadenas de forma incorrecta si está utilizando ingenuamente funciones no conscientes de varios bytes en cadenas de varios bytes. Esto no significa que no pueda usar Unicode en PHP o que cada cadena Unicode necesite ser bendecida con utf8_encode u otras tonterías similares.
Afortunadamente, está la extensión de cadena Multibyte, que replica todas las funciones importantes de cadena de forma consciente de varios bytes. Usando mb_substr($string, 0, 1, 'UTF-8') en la cadena anterior devuelve correctamente 11100110 10111100 10100010, que es todo el carácter «漢». Debido a que las funciones mb_ ahora tienen que pensar realmente en lo que están haciendo, necesitan saber en qué codificación están trabajando. Por lo tanto, cada función mb_ acepta un parámetro $encoding también. Alternativamente, se puede configurar globalmente para todas las funciones mb_ utilizando mb_internal_encoding.
Usar y abusar del manejo de codificaciones de PHP
Todo el problema del (no)soporte de PHP para Unicode es que simplemente no le importa. Las cadenas son secuencias de bytes para PHP. Qué bytes en particular no importa. PHP no hace nada con cadenas, excepto mantenerlas almacenadas en la memoria. PHP simplemente no tiene ningún concepto de caracteres o codificaciones. Y a menos que intente manipular cadenas, tampoco necesita hacerlo; simplemente se aferra a bytes que pueden o no ser interpretados como caracteres por otra persona. El único requisito que PHP tiene de codificaciones es que el código fuente PHP necesita ser guardado en una codificación compatible con ASCII. El analizador PHP está buscando ciertos caracteres que le indiquen qué hacer. $00100100) indica el inicio de una variable, =00111101) una asignación, "00100010) el inicio y el final de una cadena y así sucesivamente. Cualquier otra cosa que no tenga un significado especial para el analizador se toma simplemente como una secuencia de bytes literal. Eso incluye cualquier cosa entre comillas, como se discutió anteriormente. Esto significa lo siguiente:
-
No puede guardar el código fuente PHP en una codificación incompatible con ASCII. Por ejemplo, en UTF-16 a
"está codificado como00000000 00100010. Para PHP, que intenta leer todo como ASCII, es un byteNULseguido de un byte".PHP probablemente tendrá un contratiempo si todos los demás caracteres que encuentre son un byteNUL. -
Puede guardar el código fuente PHP en cualquier codificación compatible con ASCII. Si los primeros 128 puntos de código de una codificación son idénticos a ASCII, PHP puede analizarlos. Todos los caracteres que son de alguna manera significativos para PHP están dentro de los 128 puntos de código definidos por ASCII. Si los literales de cadena contienen algún punto de código más allá de eso, a PHP no le importa. Puede guardar código fuente PHP en ISO-8859-1, Mac Roman, UTF-8 o cualquier otra codificación compatible con ASCII. Los literales de cadena en su script tendrán la codificación con la que guardó su código fuente.
-
Cualquier archivo externo que procese con PHP puede estar en la codificación que desee. Si PHP no necesita analizarlo, no hay requisitos que cumplir para mantener al analizador PHP satisfecho.
$foo = file_get_contents('bar.txt');por encima de simplemente leer los bits en el
bar.txten la variable$foo. PHP no intenta interpretar, convertir, codificar o de otra manera jugar con el contenido. El archivo puede incluso contener datos binarios como una imagen,a PHP no le importa. -
Si las codificaciones internas y externas tienen que coincidir, tienen que coincidir. Un caso común es la localización, donde el código fuente contiene algo como
echo localize('Foobar')y un archivo de localización externo contiene algo parecido a esto:msgid "Foobar"msgstr "フーバー"Ambas cadenas» Foobar » deben tener una representación de bits idéntica si desea encontrar la localización correcta.Si el código fuente se guardaba en ASCII pero el archivo de localización en UTF-16, las cadenas no coincidirían.Sería necesario algún tipo de conversión de codificación o el uso de una función de coincidencia de cadenas de codificación.
El lector astuto podría preguntarse en este punto si es posible guardar una, por ejemplo, secuencia de bytes UTF-16 dentro de un literal de cadena de un archivo de código fuente codificado en ASCII, a la que la respuesta sería: absolutamente.
echo "UTF-16";Si puede traer su editor de texto para guardar las partes echo " y "; en ASCII y solo UTF-16 en UTF-16, esto funcionará bien. La representación binaria necesaria para eso se ve así:
01100101 01100011 01101000 01101111 00100000 00100010e c h o "11111110 11111111 00000000 01010101 00000000 01010100(UTF-16 marker) U T00000000 01000110 00000000 00101101 00000000 00110001F - 100000000 00110110 00100010 001110116 " ;La primera línea y los dos últimos bytes ASCII. El resto es UTF-16 con dos bytes por carácter. El marcador inicial 11111110 11111111 en la línea 2 es un marcador requerido al comienzo del texto codificado en UTF-16 (requerido por el estándar UTF-16, a PHP no le importa un comino). Este script PHP generará felizmente la cadena » UTF-16 «codificada en UTF-16, porque simplemente genera los bytes entre las dos comillas dobles, que representan el texto» UTF-16 » codificado en UTF-16. Sin embargo, el archivo de código fuente no es ASCII ni UTF-16 completamente válido, por lo que trabajar con él en un editor de texto no será muy divertido.
En pocas palabras
PHP soporta Unicode, o de hecho cualquier codificación, muy bien, siempre y cuando se cumplan ciertos requisitos para mantener al analizador feliz y el programador sepa lo que está haciendo. En realidad, solo debe tener cuidado al manipular cadenas, lo que incluye cortar, recortar, contar y otras operaciones que deben realizarse a nivel de caracteres en lugar de a nivel de bytes. Si no estás «haciendo nada» con tus cadenas además de leerlas y publicarlas, difícilmente tendrás problemas con el soporte de codificaciones de PHP que no tendrías en ningún otro lenguaje también.
Lenguajes compatibles con codificación
¿Qué significa que un idioma admita Unicode entonces? Javascript, por ejemplo, es compatible con Unicode. De hecho, cualquier cadena en Javascript está codificada en UTF-16. De hecho, es lo único con lo que se ocupa Javascript. No puede tener una cadena en Javascript que no esté codificada en UTF-16. Javascript adora a Unicode en la medida en que no hay facilidad para tratar con ninguna otra codificación en el lenguaje principal. Dado que Javascript se ejecuta con mayor frecuencia en un navegador, no es un problema, ya que el navegador puede manejar la logística mundana de codificación y decodificación de entrada y salida.
Otros idiomas son simplemente compatibles con la codificación. Internamente almacenan cadenas en una codificación particular, a menudo UTF-16. A su vez, deben ser informados o intentar detectar la codificación de todo lo que tiene que ver con el texto. Necesitan saber en qué codificación se guarda el código fuente, en qué codificación está un archivo que se supone que deben leer, en qué codificación desea generar texto; y convierten codificaciones sobre la marcha según sea necesario con alguna manifestación de Unicode como intermediario. Están haciendo lo mismo que puedes/deberías/necesitas hacer en PHP de forma semiautomática detrás de escena. Eso no es ni mejor ni peor que PHP, simplemente diferente. Lo bueno de esto es que las funciones de lenguaje estándar que se ocupan de cadenas simplemente Funcionan™, mientras que en PHP uno necesita prestar atención a si una cadena puede contener caracteres de varios bytes o no y elegir las funciones de manipulación de cadenas en consecuencia.
Las profundidades de Unicode
Dado que Unicode trata con muchos scripts diferentes y muchos problemas diferentes, tiene mucha profundidad. Por ejemplo, el estándar Unicode contiene información para problemas como la unificación de ideogramas CJK. Es decir, información de que dos o más caracteres chinos/japoneses/coreanos representan el mismo carácter en métodos de escritura ligeramente diferentes. O reglas sobre la conversión de minúsculas a mayúsculas, viceversa y ida y vuelta, que no siempre es tan sencillo en todos los scripts como en la mayoría de los scripts de origen latino de Europa occidental. Algunos caracteres también se pueden representar usando diferentes puntos de código. La letra «ö», por ejemplo, se puede representar usando el punto de código U + 00F6 («LETRA PEQUEÑA LATINA O CON DIÉRESIS») o como los dos puntos de código U+006F («LETRA PEQUEÑA LATINA O») y U+0308 («COMBINACIÓN DE DIÉRESIS»), es decir, la letra» o «combinada con»». En UTF-8, esa es la secuencia de dos bytes 11000011 10110110 o la secuencia de tres bytes 01101111 11001100 10001000, que representan el mismo carácter legible por humanos. Como tal, hay reglas que rigen la Normalización dentro del estándar Unicode, es decir, cómo se puede convertir una de estas formas en la otra. Esto y mucho más está fuera del alcance de este artículo, pero uno debe ser consciente de ello.
TL final;DR
- El texto es siempre una secuencia de bits que debe traducirse a texto legible por humanos mediante tablas de búsqueda. Si se utiliza la tabla de búsqueda incorrecta, se utiliza el carácter incorrecto.
- En realidad, nunca estás tratando directamente con «caracteres» o «texto», siempre estás tratando con bits vistos a través de varias capas de abstracciones. Los resultados incorrectos son un signo de que una de las capas de abstracción está fallando.
- Si dos sistemas se comunican entre sí, siempre deben especificar en qué codificación quieren comunicarse. El ejemplo más simple de esto es este sitio web que le dice a su navegador que está codificado en UTF-8.
- En esta época, la codificación estándar es UTF-8, ya que puede codificar prácticamente cualquier carácter de interés, es compatible con la base ASCII de facto y, no obstante, es relativamente eficiente en espacio para la mayoría de los casos de uso.
- Otras codificaciones todavía tienen ocasionalmente sus usos, pero debería tener una razón concreta para querer lidiar con los dolores de cabeza asociados con conjuntos de caracteres que solo pueden codificar un subconjunto de Unicode.
- Los días de un byte = un carácter han terminado y tanto los programadores como los programas necesitan ponerse al día con esto.
Ahora ya no debería tener excusas la próxima vez que confunda un texto.
-
Sí, eso significa que ASCII se puede almacenar y transferir usando solo 7 bits y a menudo lo es. No, esto no está dentro del alcance de este artículo y, en aras de la argumentación, asumiremos que el bit más alto está «desperdiciado» en ASCII. ↩
-
Y si no lo es, será extendido. Ya lo ha sido varias veces. note
-
Tenga en cuenta que cuando estoy usando el término «comenzar» junto con «byte», lo digo desde el punto de vista legible por humanos. use
-
Lea detenidamente la especificación UTF-8 si desea seguir esto con lápiz y papel. Hey
-
Hey, soy programador, no biólogo. ↩
-
Y, por supuesto, no habrá copia de seguridad reciente. ↩
-
Un «carácter Unicode» es un punto de código en la tabla Unicode. «あ» no es un carácter Unicode, es la letra Hiragana あ. Hay un punto de código Unicode para ello, pero eso no convierte a la letra en un carácter Unicode. Un » carácter UTF-8 «es un oxímoron, pero se puede estirar para significar lo que técnicamente se llama una» secuencia UTF-8″, que es una secuencia de bytes de uno, dos, tres o cuatro bytes que representan un carácter Unicode. Ambos términos se usan a menudo en el sentido de «cualquier letra que no forme parte de mi teclado», lo que significa absolutamente nada. David
-
http://www.php.net/manual/en/function.utf8-encode.php David
Sobre el autor
David C. Zentgraf es un desarrollador web que trabaja en parte en Japón y Europa y es habitual en el desbordamiento de pila.Si tienes comentarios, críticas o adiciones, no dudes en probar @deceze en Twitter,adivinar su dirección de correo electrónico o buscarla utilizando métodos tradicionales.Este artículo fue publicado en kunststube.net Y no, no hay una palabra sucia en «Kunststube».