amit minden programozónak feltétlenül, pozitívan tudnia kell a kódolásokról és a karakterkészletekről a szöveghez
Ha számítógéppel foglalkozik, tudnia kell a kódolásokról. Pont. Igen, még akkor is, ha csak e-maileket küld. Még akkor is, ha csak e-maileket kap. Nem kell minden részletet megértenie, de legalább tudnia kell, miről szól ez az egész “kódolás”. Először a jó hír: bár a téma zavaros és zavaros lehet, az alapötlet nagyon, nagyon egyszerű.
Ez a cikk a kódolásokról és a karakterkészletekről szól. Joel Spolsky cikke az abszolút Minimum címmel minden szoftverfejlesztőnek feltétlenül, pozitívan tudnia kell az Unicode-ról és a Karakterkészletekről (nincs mentség!) egy szép bevezetés a témához, és nagyon élvezem, hogy egyszer-egyszer elolvasom. Habozok utalni az emberekre, akiknek nehézségeik vannak a kódolási problémák megértésével, bár mivel, miközben szórakoztató, elég könnyű a tényleges technikai részleteken. Remélem, hogy ez a cikk több fényt deríthet arra, hogy pontosan mi a kódolás, és miért csavarja fel az összes szöveget, amikor a legkevésbé szüksége van rá. Ez a cikk a fejlesztőknek szól (a PHP-re összpontosítva), de minden számítógép-felhasználónak képesnek kell lennie arra, hogy profitáljon belőle.
az alapok tisztázása
valamilyen szinten mindenki tisztában van ezzel, de valahogy úgy tűnik, hogy ez a tudás hirtelen eltűnik a szövegről folytatott beszélgetésben, ezért először vegyük ki: a számítógép nem tárolhat “betűket”, “számokat”, “képeket” vagy bármi mást. Az egyetlen dolog, amit tárolhat és dolgozhat, a bitek. Egy bitnek csak két értéke lehet: yes vagy notrue vagy false1 vagy vagy bármi más, amit ezt a két értéket szeretné hívni. Mivel a számítógép villamos energiával működik, a “tényleges” bit egy villanás, amely vagy ott van, vagy nincs. Az emberek esetében ez általában a 1 és 0 használatával jelenik meg, és ebben a cikkben ragaszkodni fogok ehhez az egyezményhez.
ahhoz, hogy biteket használjunk, hogy a biteken kívül bármit is képviseljünk, szabályokra van szükségünk. Át kell alakítanunk egy bitsorozatot betűkké, számokká és képekké egy kódolási sémával, vagy röviden kódolással. Mint ez:
01100010 01101001 01110100 01110011b i t sebben a kódolásban a 01100010 A “b” betűt jelenti, 01101001 az “i” betűt, 01110100 A “t” és 01110011 az “S” – hez. Egy bizonyos bitsorozat egy betűt, egy betű pedig egy bizonyos bitsorozatot jelent. Ha tudod tartani ezt a fejedben 26 betűk, vagy nagyon gyors keres dolgokat egy táblázatban, akkor olvasni Bit, mint egy könyv.
a fenti kódolási séma történetesen ASCII. A 1s és 0s karakterláncok nyolc bit részekre vannak bontva (röviden egy bájt). Az ASCII kódolás megad egy táblázatot, amely bájtokat fordít ember által olvasható betűkre. Itt van egy rövid részlet az asztalról:
| bits | character |
|---|---|
01000001 |
A |
01000010 |
B |
01000011 |
C |
01000100 |
D |
01000101 |
E |
01000110 |
F |
There are 95 human readable az ASCII táblázatban megadott karakterek, beleértve az A-tól Z-ig terjedő betűket nagy-és kisbetűkkel, a 0-tól 9-ig terjedő számokat, egy maroknyi írásjelet és olyan karaktereket, mint a dollár szimbólum, az ampersand és néhány más. 33 értéket is tartalmaz olyan dolgokhoz, mint a space, a line feed, a tab, a backspace stb. Ezek önmagukban nem nyomtathatók, de valamilyen formában mégis láthatóak és közvetlenül az emberek számára hasznosak. Számos érték csak a számítógép számára hasznos, például kódok a szöveg kezdetének vagy végének jelzésére. Összesen 128 karakter van meghatározva az ASCII kódolásban, ami szép kerek szám (számítógépekkel foglalkozó emberek számára), mivel minden lehetséges 7 bites kombinációt használ (000000000000010000010 keresztül 1111111).1
és itt van ez a módja annak, hogy az ember által olvasható szöveget csak 1s és 0s.
01001000 01100101 01101100 01101100 01101111 00100000 01010111 01101111 01110010 01101100 01100100“Hello World”
fontos kifejezések
ha valamit ASCII-ben szeretne kódolni, kövesse a táblázatot jobbról balra, a bitek betűit helyettesítve. Ha egy bitsorozatot ember által olvasható karakterekké szeretne dekódolni, kövesse a táblázatot balról jobbra, a biteket betűkkel helyettesítve.
encode |en blokklánc-Bank-band|
ige
konvertálás kódolt formábankód |k blokklánc|
főnév
szavak, betűk, ábrák vagy más szimbólumok rendszere, amelyek más szavakat, betűket stb.helyettesítenek.
a kódolás azt jelenti, hogy valamit használunk valami más ábrázolására. A kódolás az a szabálykészlet, amellyel valamit átalakíthatunk egyik reprezentációból a másikba.
egyéb kifejezések, amelyek ebben az összefüggésben tisztázást érdemelnek:
karakterkészlet, karakterkészlet a kódolható karakterek halmaza. “Az ASCII kódolás 128 karakterből álló karakterkészletet foglal magában.”Lényegében a “kódolás” szinonimája. kódoldal olyan kódok “oldala”, amelyek egy karaktert számhoz vagy bitsorozathoz rendelnek. Más néven “az asztal”. Lényegében a “kódolás” szinonimája. húr a húr egy csomó elem, amelyet összefűztek. A bit karakterlánc egy csomó bit, például01010011. A karakterlánc egy csomó karakter,like this. A “szekvencia” szinonimája.
bináris, oktális, decimális, hex
a számok írásának számos módja van. 10011111 binárisan 237 oktálisban 159 decimálisban 9f hexadecimális. Mindegyik ugyanazt az értéket képviseli, de a hexadecimális rövidebb és könnyebben olvasható, mint a bináris. Én ragaszkodni fog a bináris egész ezt a cikket, hogy a lényeg az egész jobb, és kímélje az olvasó egy réteg absztrakció. Ne ijedjen meg, ha máshol más jelölésekben említett karakterkódokat lát, ez ugyanaz.
Excusez-moi?
most, hogy tudjuk, miről beszélünk, mondjuk ki: 95 karakter tényleg nem sok, ha nyelvekről van szó. Ez magában foglalja az alapokat az angol, de mi a helyzet az írás egy risqu Bitcoin levél francia? A Stractinen Actainggesgesetz németül? Meghívó egy svéd nyelvű SM XXL-RG-re? Az ASCII – ben nem. Nincs előírás, hogy hogyan képviselik a leveleket, é, ß, ü, ä, ö vagy å ASCII, így nem tudom használni őket.
“de nézd meg,” az európaiak azt mondták,”egy közös számítógép 8 Bit a byte, ASCII pazarlás egy egész bit, amely mindig be van állítva 0! Tudjuk használni, hogy kicsit szorítani egy egész ‘ nother 128 értékek ebbe a táblázatba!”És így is tettek. De még így is több mint 128 módja van a magánhangzó simogatásának, szeletelésének, vágásának és pontozásának. Az összes európai nyelvben használt betűk és squiggles nem minden változata ábrázolható ugyanabban a táblázatban, legfeljebb 256 értékkel. Tehát a világ végül rengeteg kódolási sémával, szabványokkal, de facto szabványokkal és félszabványokkal jött létre, amelyek mind a karakterek különböző részhalmazát fedik le. Valakinek meg kellett írnia egy dokumentumot a svéd nyelvről csehül, megállapította, hogy egyetlen kódolás sem fedte le mindkét nyelvet, és feltalált egyet. Vagy úgy gondolom, hogy számtalanszor átment.
és ne feledkezzünk meg az orosz, Hindi, arab, héber, koreai és minden más nyelvről, amely jelenleg aktív használatban van ezen a bolygón. Nem is beszélve azokról, amelyek már nem használatosak. Miután megoldotta a vegyes nyelvű dokumentumok írásának problémáját ezeken a nyelveken, próbálja ki magát kínaiul. Vagy Japán. Mindkettő több tízezer karaktert tartalmaz. 256 lehetséges értéke van egy 8 bites bájtnak. Menj!
Többbájtos kódolások
egy 256 karakternél több karaktert használó nyelv karaktereit betűkre leképező tábla létrehozásához egy bájt egyszerűen nem elegendő. Két bájt (16 bit) használatával 65 536 különálló értéket lehet kódolni. A BIG-5 egy ilyen kettős bájtos kódolás. Ahelyett, hogy egy bitsorozatot nyolcas blokkokra bontana, 16-os blokkokra bontja, és van egy nagy (mármint nagy) táblázata, amely meghatározza, hogy a bitek egyes kombinációi melyik karakterhez kapcsolódnak. A BIG-5 alapformájában többnyire hagyományos kínai karaktereket fed le. A GB18030 egy másik kódolás, amely lényegében ugyanazt teszi, de mind hagyományos, mind egyszerűsített kínai karaktereket tartalmaz. Mielőtt megkérdezné, igen, vannak olyan kódolások, amelyek csak az egyszerűsített kínai nyelvet fedik le. Most már nem lehet csak egy Kódolás, ugye?
itt egy kis részlet a GB18030 táblázatból:
| bits | character |
|---|---|
10000001 01000000 |
丂 |
10000001 01000001 |
丄 |
10000001 01000010 |
丅 |
10000001 01000011 |
丆 |
10000001 01000100 |
丏 |
GB18030 covers quite a range of characters (including a large part of latin karakterek), de a végén még egy speciális kódolási formátum a sok közül.
Unicode a zavart

végül valaki elég volt a rendetlenség, és elindult, hogy kovácsolni egy gyűrűt kötni őket létrehozni egy Kódolás szabvány az összes kódolási szabvány egységesítésére. Ez a szabvány Unicode. Alapvetően meghatározza az 1 114 112 kódpontból álló hatalmas táblázatot, amely mindenféle betűhöz és szimbólumhoz használható. Ez bőven elég az összes európai, Közel-Keleti, távol-keleti, déli, északi, nyugati, pre-történész és jövőbeli karakter kódolásához, akikről az emberiség tud.2 az Unicode használatával gyakorlatilag bármilyen nyelvet tartalmazó dokumentumot írhat a számítógépbe beírható karakterek segítségével. Ezt vagy lehetetlen, vagy nagyon nehéz volt megszerezni, mielőtt az Unicode jött. Még egy nem hivatalos rész is van a Klingon számára Unicode-ban. Valójában az Unicode elég nagy ahhoz, hogy lehetővé tegye a nem hivatalos, magánhasználatú területeket.
szóval, hány bitet használ az Unicode ezeknek a karaktereknek a kódolására? Nincs. Mivel az Unicode nem kódolás.
zavaros? Úgy tűnik, sokan vannak. Az Unicode elsősorban a karakterek kódpontjainak táblázatát határozza meg. Ez egy divatos módja annak, hogy “a 65 az A, A 66 A B, a 9731 pedig az ++” (komolyan, igen). Az, hogy ezeket a kódpontokat valójában bitekké kódolják, más téma. 1 114 112 különböző érték ábrázolásához két bájt nem elegendő. Három bájt van, de három bájttal gyakran kényelmetlen dolgozni, tehát négy bájt lenne a kényelmes minimum. De, hacsak nem valóban kínai vagy más, nagy számokkal rendelkező karaktereket használ, amelyek kódolása sok bitet igényel, soha nem fogja használni a négy bájt hatalmas darabját. Ha az “a” betűt mindig 00000000 00000000 00000000 01000001, “B” mindig 00000000 00000000 00000000 01000010 és így tovább kódolták, minden dokumentum a szükséges Méret négyszeresére duzzad.
ennek optimalizálása érdekében többféle módon lehet kódolni az Unicode kódpontokat bitekre. Az UTF – 32 olyan kódolás, amely az összes Unicode kódpontot 32 bit segítségével kódolja. Vagyis karakterenként négy bájt. Nagyon egyszerű, de gyakran sok helyet pazarol. Az UTF-16 és az UTF-8 változó hosszúságú kódolások. Ha egy karakter egyetlen bájt segítségével ábrázolható (mivel a kódpontja nagyon kis szám), az UTF-8 egyetlen bájttal kódolja. Ha két bájtot igényel, akkor két bájtot fog használni, és így tovább. Bonyolult módon használhatja a bájt legmagasabb bitjeit annak jelzésére, hogy egy karakter hány bájtból áll. Ez helyet takaríthat meg, de helyet is pazarolhat, ha ezeket a jelbiteket gyakran kell használni. Az UTF-16 középen van, legalább két bájtot használva, szükség szerint akár négy bájtra is növekszik.
| character | encoding | bits |
|---|---|---|
| A | UTF-8 | 01000001 |
| A | UTF-16 | 00000000 01000001 |
| A | UTF-32 | 00000000 00000000 00000000 01000001 |
| あ | UTF-8 | 11100011 10000001 10000010 |
| あ | UTF-16 | 00110000 01000010 |
| あ | UTF-32 | 00000000 00000000 00110000 01000010 |
és ez minden. Az Unicode egy nagy tábla, amely karaktereket rendel a számokhoz, és a különböző UTF kódolások meghatározzák, hogyan kódolják ezeket a számokat bitként. Összességében az Unicode egy újabb kódolási séma. Nincs benne semmi különös, csak megpróbál mindent lefedni, miközben továbbra is hatékony. És ez jó dolog.
Kódpontok
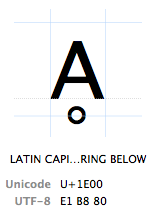
a karaktereket az “Unicode kódpontjuk”jelöli. Az Unicode kódpontokat hexadecimálisan írják (hogy a számok rövidebbek legyenek), amelyet egy “U+” előz meg (éppen ezt teszik, nincs más jelentése, mint “ez egy Unicode kódpont”). A karakternek az U+1E00 Unicode kódpontja van. Más (tizedes) szavakkal ez az Unicode tábla 7680.karaktere. Hivatalosan “LATIN nagybetűvel a gyűrűvel” hívják.
TL; DR
a fentiek összefoglalása: bármely karakter sokféle bitsorozatban kódolható, és bármely adott bitsorozat sok különböző karaktert képviselhet, attól függően, hogy melyik kódolást használják az olvasáshoz vagy íráshoz. Ennek oka egyszerűen az, hogy a különböző kódolások karakterenként eltérő számú bitet és különböző értékeket használnak a különböző karakterek ábrázolásához.
| bits | encoding | characters |
|---|---|---|
11000100 01000010 |
Windows Latin 1 | ÄB |
11000100 01000010 |
Mac Roman | ƒB |
11000100 01000010 |
GB18030 | 腂 |
| characters | encoding | bits |
|---|---|---|
| F ++ | Windows Latin 1 | 01000110 11111000 11110110 |
| F ++ | Mac Roman | 01000110 10111111 10011010 |
| f a-8 | 01000110 11000011 10111000 11000011 10110110 |
tévhitek, zűrzavarok és problémák
mindezek után eljutunk a sok felhasználó és programozó által naponta tapasztalt tényleges problémákhoz, hogy ezek a problémák hogyan kapcsolódnak a fentiekhez, és mi a megoldás. A legnagyobb probléma az összes:
miért az Isten nevében vannak a karakterek zavaros?!
ÉGÉìÉRÅ;Ha ez a $string egybájtos kódolásban volt, akkor ez adja meg az első karaktert. De csak azért, mert a” karakter “egybeesik a” byte ” -val egy bájtos kódolásban. A PHP egyszerűen megadja nekünk az első bájtot anélkül, hogy a “karakterekre”gondolnánk. A karakterláncok BÁJTSOROZATOK a PHP-hez, semmi több, semmi kevesebb. Ez az egész “olvasható karakter” dolog emberi dolog, és a PHP-t nem érdekli.
01000100 01101111 01101110 00100111 01110100D o n ' t01100011 01100001 01110010 01100101 00100001c a r e !ugyanez vonatkozik számos szabványos funkcióra, mint például substrstrpostrim és így tovább. A nem támogatás akkor merül fel, ha eltérés van egy bájt és egy karakter hossza között.
11100110 10111100 10100010 11100101 10101101 10010111漢 字
a $string használatával a fenti karakterláncon ismét megadjuk az első bájtot, ami 11100110. Más szavakkal, a hárombájtos karakter egyharmada”++”. 11100110 önmagában érvénytelen UTF-8 szekvencia, tehát a karakterlánc most megtört. Ha úgy érzi, hogy, akkor próbálja értelmezni, hogy valamilyen más kódolás, ahol 11100110 egy érvényes karakter, ami azt eredményezi, hogy néhány véletlenszerű karaktert. Jó szórakozást, de ne használja a termelésben.
és valójában ez minden. A “PHP natívan nem támogatja az Unicode-ot” egyszerűen azt jelenti, hogy a legtöbb PHP függvény egy bájtot = egy karaktert feltételez, ami oda vezethet, hogy több bájtos karaktereket kettévág, vagy helytelenül számítja ki a karakterláncok hosszát, ha naiv módon nem több bájtos tudatos funkciókat használ több bájtos karakterláncokon. Ez nem azt jelenti, hogy nem használhatja a Unicode-ot a PHP-ben, vagy hogy minden Unicode-karakterláncot meg kell áldani a utf8_encode vagy más hasonló ostobasággal.
Szerencsére ott van a Többbájtos karakterlánc-kiterjesztés, amely az összes fontos karakterlánc-funkciót többbájtos tudatos módon replikálja. A mb_substr($string, 0, 1, 'UTF-8') használata a fenti karakterláncon helyesen adja vissza a 11100110 10111100 10100010 értéket, amely az egész ” ++ ” karakter. Mivel amb_ függvények most már ténylegesen gondolni, hogy mit csinálnak, tudniuk kell, hogy milyen kódolás dolgoznak. Ezért minden mb_függvény Elfogad egy $encoding paramétert is. Alternatív megoldásként ez globálisan beállítható az összes mb_ függvényhez a mb_internal_encodinghasználatával.
A PHP kódolások kezelésének használata és visszaélése
a PHP (nem)Unicode támogatásának teljes kérdése az, hogy egyszerűen nem érdekli. A karakterláncok BÁJTSOROZATOK a PHP-hez. Milyen bájtok különösen nem számít. A PHP nem csinál semmit a karakterláncokkal, csak a memóriában tárolja őket. A PHP-nek egyszerűen nincs fogalma sem karakterekről, sem kódolásokról. És hacsak nem próbálja manipulálni a húrokat, akkor sem kell; csak olyan bájtokhoz ragaszkodik, amelyeket valaki más karakterként értelmezhet vagy nem. A PHP egyetlen követelménye a kódolás, hogy a PHP forráskódját ASCII-kompatibilis kódolásba kell menteni. A PHP elemző bizonyos karaktereket keres, amelyek megmondják neki, mit kell tennie. $00100100) egy változó kezdetét jelzi, =00111101) egy hozzárendelés, "00100010) a karakterlánc kezdete és vége stb. Bármi mást, amelynek nincs különösebb jelentősége az elemző számára, csak szó szerinti bájtsorozatnak tekintjük. Ez magában foglalja az idézetek közötti bármit, amint azt fentebb tárgyaltuk. Ez a következőket jelenti:
-
A PHP forráskódját nem lehet ASCII-inkompatibilis kódolásba menteni. Például az UTF-16 – ban a
"kódoltmint00000000 00100010. A PHP-hez, amely mindent ASCII-ként próbál olvasni, ez egyNULbájt, amelyet egy"követ.PHP valószínűleg kap egy csuklás, ha minden más karakter talál egyNULbyte. -
A PHP forráskódját bármilyen ASCII-kompatibilis kódolásba mentheti. Ha egy Kódolás első 128 kódpontjaazonos az ASCII – vel, a PHP elemezheti. Minden olyan karakter, amely bármilyen módon jelentős a PHP számára, az ASCII által meghatározott 128 kódponton belül van. Ha a karakterlánc-literálok ezen túl tartalmaznak kódpontokat, a PHP-t nem érdekli. Mentheti PHP sourcecode ISO-8859-1, Mac Roman, UTF-8 vagy bármely más ASCII-kompatibilis kódolás. A karakterlánc literálok a script willhave bármilyen kódolás mentette a forráskódot, mint.
-
bármely külső fájl, amelyet PHP-vel dolgoz fel, bármilyen kódolásban lehet. Ha a PHP-nek nem kell elemeznie, akkor nincs követelmény, hogy megfeleljen a PHP elemző boldogságának.
$foo = file_get_contents('bar.txt');a fentiek egyszerűen leolvassák a
bar.txtbitjeit a$foováltozóba. A PHP nem próbálja értelmezni, konvertálni, kódolni vagy más módon hegedülni a tartalommal. A fájl bináris adatokat is tartalmazhat,például képet, a PHP nem érdekli. -
Ha a belső és külső kódolásoknak egyezniük kell, akkor egyezniük kell. Gyakori eset a lokalizáció, ahola forráskód valami hasonlót tartalmaz
echo localize('Foobar')és egy külső lokalizációs fájl tartalmaz valamit ennek mentén:msgid "Foobar"msgstr "フーバー"mindkét “Foobar” karakterláncnak azonos bitreprezentációval kell rendelkeznie, ha meg akarja találni a helyes lokalizációt.Ha a forráskódot ASCII-ben mentették, de a lokalizációs fájlt UTF-16-ban, a karakterláncok nem egyeznek.Vagy valamilyen kódolási átalakításra lenne szükség, vagy egy Kódolás-tudatos karakterlánc-illesztési funkció használatára.
Az ügyes olvasó ezen a ponton megkérdezheti, hogy lehet-e menteni egy, mondjuk, UTF-16 bájtos szekvenciát egy ASCII kódolású forráskód karakterláncában, amelyre a válasz a következő lenne: abszolút.
echo "UTF-16";Ha hozhat a szövegszerkesztő menteni a echo " és "; alkatrészek ASCII és csak UTF-16 UTF-16, ez működni fog csak finom. A szükséges bináris ábrázolás így néz ki:
01100101 01100011 01101000 01101111 00100000 00100010e c h o "11111110 11111111 00000000 01010101 00000000 01010100(UTF-16 marker) U T00000000 01000110 00000000 00101101 00000000 00110001F - 100000000 00110110 00100010 001110116 " ; az első sor és az utolsó két bájt ASCII. A többi UTF-16, karakterenként két bájttal. A vezető 11111110 11111111 a 2. sorban az UTF-16 kódolású szöveg elején szükséges jelölő (az UTF-16 szabvány előírja, a PHP nem ad átkozottul). Ez a PHP szkript boldogan adja ki az UTF-16-ban kódolt “UTF-16” karakterláncot, mert egyszerűen kiadja a bájtokat a két dupla idézet között, ami történetesen az UTF-16-ban kódolt “UTF-16” szöveget képviseli. A forráskód fájl sem teljesen érvényes ASCII, sem UTF-16, így a szövegszerkesztőben való munka nem lesz sok móka.
alsó sor
a PHP támogatja az Unicode-ot, vagy valójában bármilyen kódolást, csak rendben, mindaddig, amíg bizonyos követelmények teljesülnek, hogy az elemző boldog legyen, és a programozó tudja, mit csinál. Valójában csak a karakterláncok manipulálásakor kell óvatosnak lennie, amely magában foglalja a szeletelést, a vágást, a számlálást és más műveleteket, amelyeknek karakterszinten kell történniük, nem pedig bájtszinten. Ha nem” csinálsz semmit ” a karakterláncokkal az olvasáson és a kimeneten kívül, akkor aligha lesz problémája a PHP által támogatott kódolásokkal, amelyek más nyelven sem lennének.
Kódolástudatos nyelvek
mit jelent az, hogy egy nyelv Támogatja az Unicode-ot? A Javascript például támogatja az Unicode-ot. Valójában a Javascript bármely karakterlánca UTF-16 kódolású. Valójában ez az egyetlen dolog, amellyel a Javascript foglalkozik. A Javascript-ben nem lehet olyan karakterlánc, amely nincs UTF-16 kódolva. A Javascript annyira imádja az Unicode-ot, hogy nincs lehetőség más kódolás kezelésére az alapnyelven. Mivel a Javascript leggyakrabban egy böngészőben fut, ez nem jelent problémát, mivel a böngésző képes kezelni a bemenetek és kimenetek kódolásának és dekódolásának hétköznapi logisztikáját.
más nyelvek egyszerűen kódolástudatosak. Belsőleg karakterláncokat tárolnak egy adott kódolásban, gyakran UTF-16. Viszont meg kell mondani nekik, vagy meg kell próbálniuk észlelni mindazt, ami a szöveghez kapcsolódik. Tudniuk kell, hogy a forráskód milyen kódolásban van mentve, milyen kódolásban kell olvasniuk egy fájlt, milyen kódolásban szeretné kiadni a szöveget; és szükség szerint menet közben konvertálják a kódolásokat az Unicode valamilyen megnyilvánulásával, mint közvetítővel. Ugyanazt csinálják, amit a PHP-ben félig automatikusan a színfalak mögött lehet/kell/kell tennie. Ez sem jobb, sem rosszabb, mint a PHP, csak más. Az a jó benne, hogy a karakterláncokkal foglalkozó standard nyelvi függvények csak működnek, míg a PHP-ben némi figyelmet kell fordítani arra, hogy egy karakterlánc tartalmazhat-e több bájtos karaktereket, vagy sem, és ennek megfelelően válassza ki a karakterlánc-manipulációs függvényeket.
az Unicode mélysége
mivel az Unicode sok különböző szkriptet és sok különböző problémát kezel, nagyon mély. Például az Unicode szabvány információkat tartalmaz olyan problémákról, mint a CJK ideográf egyesítése. Ez azt jelenti, hogy két vagy több kínai / japán / koreai karakter valójában ugyanazt a karaktert képviseli kissé eltérő írásmódokban. Vagy a kisbetűk nagybetűkre, fordítva és oda-vissza konvertálására vonatkozó szabályok, amelyek nem mindig olyan egyértelműek minden szkriptben, mint a legtöbb nyugat-európai Latin eredetű szkriptben. Egyes karakterek különböző kódpontokkal is ábrázolhatók. A levél “š” például lehet képviselt kóddal pont U+00F6 (“KIS LATIN BETŰT O VAL DIAERESIS”), vagy a két kód pontot U+006F (“KIS LATIN BETŰT O”), U+0308 (“ÖTVÖZI DIAERESIS”), hogy az “o” betű együtt “”. Az UTF-8-ban ez vagy a kettős bájtos sorrend 11000011 10110110 vagy a három bájtos sorrend 01101111 11001100 10001000, mindkettő ugyanazt az ember által olvasható karaktert képviseli. Mint ilyen, vannak szabályok A normalizálásra az Unicode szabványon belül, azaz hogyan lehet ezeket a formákat átalakítani a másikba. Ez és még sok más kívül esik a cikk hatályán, de tisztában kell lennie vele.
végleges TL; DR
- a szöveg mindig bitek sorozata, amelyet keresőtáblák segítségével ember által olvasható szöveggé kell lefordítani. Ha rossz Keresési táblát használ, akkor rossz karaktert használ.
- valójában soha nem foglalkozik közvetlenül a “karakterekkel” vagy a “szöveggel”, mindig a bitekkel foglalkozik, ahogy az absztrakciók több rétegén keresztül látható. A helytelen eredmények azt jelzik, hogy az egyik absztrakciós réteg meghibásodik.
- ha két rendszer beszél egymással, mindig meg kell adniuk, hogy milyen kódolásban akarnak beszélni egymással. A legegyszerűbb példa erre ez a webhely, amely azt mondja a böngészőjének, hogy UTF-8 kódolású.
- ebben a korban a standard kódolás UTF-8, mivel gyakorlatilag bármilyen érdekes karaktert képes kódolni, visszafelé kompatibilis a de facto kiindulási ASCII-vel, és ennek ellenére a legtöbb felhasználási esetben viszonylag helytakarékos.
- más kódolásoknak alkalmanként még mindig vannak felhasználási módjai, de konkrét oka kell, hogy legyen arra, hogy foglalkozzon a karakterkészletekkel kapcsolatos fejfájásokkal, amelyek csak az Unicode egy részhalmazát képesek kódolni.
- az egy bájt = egy karakter napjai elmúltak, és mind a programozóknak, mind a programoknak fel kell zárkózniuk ehhez.
most már tényleg nincs mentség többé a következő alkalommal, amikor garble néhány szöveget.
-
Igen, ez azt jelenti, hogy az ASCII csak 7 bit használatával tárolható és továbbítható, és gyakran az is. Nem, ez nem tartozik a cikk hatálya alá, és az érvelés kedvéért feltételezzük, hogy a legmagasabb bit “elpazarolt” az ASCII-ben.
-
és ha nem, akkor meghosszabbodik. Már többször is volt.
-
kérjük, vegye figyelembe, hogy amikor a “kezdő” kifejezést a “byte” kifejezéssel együtt használom, azt az ember által olvasható szempontból értem.
-
olvassa el az UTF-8 specifikációt, ha ezt tollal és papírral szeretné követni.
-
Hé, én programozó vagyok, nem biológus.
-
és természetesen nem lesz újabb biztonsági mentés.
-
a “Unicode karakter” egy kódpont az Unicode táblában. Az “anti-Code” nem Unicode karakter, hanem a hiragana betű. Van egy Unicode kódpont, de ez nem teszi magát a levelet Unicode karakterré. Az ” UTF-8 karakter “egy oximoron, de meghosszabbítható úgy, hogy azt jelentse, amit technikailag” UTF-8 szekvenciának ” neveznek, amely egy, kettő, három vagy négy bájt bájtsorozata, amely egy Unicode karaktert képvisel. Mindkét kifejezést gyakran használják abban az értelemben, hogy “bármilyen betű, amely nem része a billentyűzetemnek”, ami semmit sem jelent. ++
-
http://www.php.net/manual/en/function.utf8-encode.php ++
A szerzőről
David C. Zentgraf egy webfejlesztő, aki részben Japánban és Európában dolgozik, és rendszeresen foglalkozik a verem túlcsordulásával.Ha visszajelzése, kritikája vagy kiegészítései vannak,kérjük, próbálja ki a @deceze-t a Twitteren, tegyen egy művelt találgatást az e-mail címére, vagy keresse meg az időigényes módszerekkel.Ez a cikk megjelent kunststube.net.és nem, nincs piszkos szó a “Kunststube” – ban.