co absolutnie, pozytywnie każdy programista musi wiedzieć o kodowaniu i zestawach znaków do pracy z tekstem
Jeśli masz do czynienia z tekstem w komputerze, musisz wiedzieć o kodowaniu. Kropka. Tak, nawet jeśli tylko wysyłasz e-maile. Nawet jeśli dopiero otrzymujesz e-maile. Nie musisz rozumieć każdego szczegółu, ale musisz przynajmniej wiedzieć, o co chodzi w tym całym „kodowaniu”. I najpierw dobra wiadomość: podczas gdy temat może być niechlujny i mylący, podstawowa idea jest naprawdę, naprawdę prosta.
Ten artykuł jest o kodowaniu i zestawach znaków. Artykuł Joela Spolsky ’ ego pt. absolutne Minimum każdy programista absolutnie, pozytywnie musi wiedzieć o Unicode i zestawach znaków (bez wymówek!) jest miłym wprowadzeniem do tematu i bardzo lubię go czytać od czasu do czasu. Waham się odsyłać do niego ludzi, którzy mają problemy ze zrozumieniem problemów z kodowaniem, ponieważ podczas zabawy jest dość lekki w rzeczywistych szczegółach technicznych. Mam nadzieję, że ten artykuł może rzucić trochę więcej światła na to, czym dokładnie jest kodowanie i dlaczego cały Twój tekst wkręca się, gdy najmniej go potrzebujesz. Ten artykuł jest skierowany do programistów (z naciskiem na PHP), ale każdy użytkownik komputera powinien być w stanie z niego skorzystać.
prostowanie podstaw
każdy jest tego świadomy na pewnym poziomie, ale jakoś ta wiedza zdaje się nagle znikać w dyskusji o tekście, więc wyjdźmy najpierw: komputer nie może przechowywać „liter”, „cyfr”, „zdjęć” lub czegokolwiek innego. Jedyne, co może przechowywać i pracować z bitami. Bit może mieć tylko dwie wartości: yes lub notrue lub false1 lub 0 lub jak chcesz nazwać te dwie wartości. Ponieważ komputer pracuje z elektrycznością,” rzeczywisty ” bit jest blipem elektryczności, który jest lub nie ma. Dla ludzi jest to zwykle reprezentowane za pomocą 1 I 0 I będę trzymać się tej konwencji w całym tym artykule.
aby używać bitów do reprezentowania czegokolwiek poza bitami, potrzebujemy reguł. Musimy przekonwertować sekwencję bitów na coś takiego jak litery, cyfry i obrazy za pomocą schematu kodowania lub kodowania w skrócie. W ten sposób:
01100010 01101001 01110100 01110011b i t sw tym kodowaniu, 01100010 oznacza literę „b”, 01101001 oznacza literę „i”, 01110100 oznacza „t” I 01110011 Dla „s”. Pewna sekwencja bitów oznacza literę, A litera oznacza pewną sekwencję bitów. Jeśli możesz trzymać to w głowie przez 26 liter lub naprawdę szybko szukasz rzeczy w tabeli, możesz czytać fragmenty jak książkę.
powyższy schemat kodowania to ASCII. Łańcuch 1S I 0s jest podzielony na części po osiem bitów każda (w skrócie bajt). Kodowanie ASCII określa tabelę tłumaczącą bajty na litery czytelne dla człowieka. Oto krótki fragment tej tabeli:
| bits | character |
|---|---|
01000001 |
A |
01000010 |
B |
01000011 |
C |
01000100 |
D |
01000101 |
E |
01000110 |
F |
There are 95 human readable znaki określone w tabeli ASCII, w tym litery od A do Z pisane dużymi i małymi literami, cyfry od 0 do 9, kilka znaków interpunkcyjnych i znaków, takich jak symbol dolara, ampersand i kilka innych. Zawiera również wartości 33 dla rzeczy takich jak spacja, kanał liniowy, karta, backspace i tak dalej. Nie są one drukowalne per se, ale nadal widoczne w jakiejś formie i użyteczne dla ludzi bezpośrednio. Wiele wartości jest użytecznych tylko dla komputera, takich jak kody oznaczające początek lub koniec tekstu. W sumie w kodowaniu ASCII zdefiniowanych jest 128 znaków, co jest ładną okrągłą liczbą (dla osób zajmujących się komputerami), ponieważ wykorzystuje wszystkie możliwe kombinacje 7 bitów (000000000000010000010 poprzez 1111111).1
i tam masz, sposób reprezentowania tekstu czytelnego dla człowieka za pomocą tylko 1S I 0 s.
01001000 01100101 01101100 01101100 01101111 00100000 01010111 01101111 01110010 01101100 01100100„Hello World”
ważne terminy
aby zakodować coś w ASCII, postępuj zgodnie z tabelą od prawej do lewej, zastępując litery bitami. Aby zdekodować ciąg bitów na znaki czytelne dla człowieka, postępuj zgodnie z tabelą od lewej do prawej, zastępując bity literami.
kodowanie|enˈkōd/
czasownik
konwersja do zakodowanej formykod|kōd /
rzeczownik
system słów, liter, cyfr lub innych symboli zastępowanych innymi słowami, literami itp.
kodowanie oznacza użycie czegoś do reprezentowania czegoś innego. Kodowanie jest zbiorem reguł, za pomocą których można konwertować coś z jednej reprezentacji na drugą.
inne terminy, które zasługują na wyjaśnienie w tym kontekście:
character set, charset zestaw znaków, które mogą być zakodowane. „Kodowanie ASCII obejmuje zestaw znaków 128 znaków.”Zasadniczo synonimem „kodowania”. strona kodowa „strona” kodów, które mapują znak na liczbę lub sekwencję bitów. „Stół”. Zasadniczo synonimem „kodowania”. string string to kilka elementów nawleczonych razem. Łańcuch bitowy to kilka bitów, jak01010011. Ciąg znaków to kilka znaków ,like this. Synonim „sekwencji”.
Binary, octal, decimal, hex
istnieje wiele sposobów zapisu liczb. 10011111 w binarnym jest 237 w ósemkowym jest 159 w dziesiętnym jest 9F w szesnastkowym. Wszystkie reprezentują tę samą wartość, ale szesnastkowy jest krótszy i łatwiejszy do odczytania niż binarny. Pozostanę przy binarnym w tym artykule, aby lepiej zrozumieć i oszczędzić czytelnikowi jednej warstwy abstrakcji. Nie należy się obawiać, aby zobaczyć kody znaków referencyjnych w innych notatkach, to wszystko to samo.
Excusez-moi?
Now that we know what we’Re talking about, let’s just say it: 95 characters really isn’t a lot when it comes to languages. It covers the basics of English, but what about writing a risqué letter in French? A zmiany drogowe w prawie niemieckim? An invitation to a in Swedish? Well, you couldn’t. Not in ASCII. Nie ma specyfikacji na temat tego, jak represent any of the letters é, ô, ü, ä, å ö lub ASCII, więc możesz ich użyć.
„ale spójrz na to,” Europejczycy powiedzieli, „we wspólnym komputerze z 8 bitami na bajt, ASCII marnuje cały bit, który jest zawsze ustawiony na0! Możemy użyć tego bitu, aby wcisnąć całą ’ nother 128 wartości do tej tabeli!”I tak zrobili. Ale mimo to, istnieje ponad 128 sposobów na obrys, cięcie, Ukośnik i kropkę samogłoski. Nie wszystkie odmiany liter i zawijasów używane we wszystkich językach europejskich mogą być przedstawione w tej samej tabeli z maksymalnie 256 wartościami. Tak więc świat skończył z bogactwem schematów kodowania, standardów, standardów de facto i pół-standardów, które wszystkie obejmują inny podzbiór znaków. Ktoś musiał napisać dokument o szwedzkim w języku czeskim, okazało się, że kodowanie nie obejmuje obu języków i wymyślił jeden. Wyobrażam sobie, że przeszło to niezliczoną ilość razy.
i nie zapomnij o rosyjskim, Hindi, arabskim, hebrajskim, koreańskim i wszystkich innych językach obecnie używanych na tej planecie. Nie wspominając o tych, które już nie są używane. Po rozwiązaniu problemu pisania dokumentów w języku mieszanym we wszystkich tych językach, WYPRÓBUJ się na chińskim. Albo Po Japońsku. Oba zawierają dziesiątki tysięcy znaków. Masz 256 możliwych wartości do bajtu składającego się z 8 bitów. Idź!
kodowanie wielobajtowe
aby utworzyć tabelę, która mapuje znaki na litery dla języka, który używa więcej niż 256 znaków, jeden bajt po prostu nie wystarczy. Używając dwóch bajtów (16 bitów), możliwe jest zakodowanie 65 536 różnych wartości. BIG-5 jest takim dwubajtowym kodowaniem. Zamiast łamać ciąg bitów na bloki po osiem, łamie go na bloki po 16 i ma dużą (mam na myśli dużą) tabelę, która określa, do którego znaku mapuje się każda kombinacja bitów. BIG-5 w swojej podstawowej formie obejmuje głównie tradycyjne chińskie znaki. GB18030 to kolejne kodowanie, które zasadniczo robi to samo, ale zawiera zarówno tradycyjne, jak i uproszczone chińskie znaki. I zanim zapytasz, tak, istnieją kodowania, które obejmują tylko Chiński Uproszczony. Nie możemy mieć tylko jednego kodowania, prawda?
oto mały fragment tabeli GB18030:
| bits | character |
|---|---|
10000001 01000000 |
丂 |
10000001 01000001 |
丄 |
10000001 01000010 |
丅 |
10000001 01000011 |
丆 |
10000001 01000100 |
丏 |
GB18030 covers quite a range of characters (including a large part of latin znaków), ale w końcu jest to kolejny wyspecjalizowany format kodowania wśród wielu.
Unicode to the confusion

wreszcie ktoś miał dość bałaganu i postanowił wykuć pierścień, aby związać je wszystkie, tworząc jedno kodowanie standard do ujednolicenia wszystkich standardów kodowania. Ten standard to Unicode. Zasadniczo definiuje ogromną tabelę z 1,114,112 punktów kodowych, które mogą być używane dla wszelkiego rodzaju liter i symboli. To wiele do zakodowania wszystkich europejskich, bliskowschodnich, Dalekowschodnich, południowych, północnych, zachodnich, przedhistorycznych i przyszłych postaci, o których ludzkość wie.2 używając Unicode, możesz napisać dokument zawierający praktycznie dowolny język, używając dowolnego znaku, który możesz wpisać na komputerze. Było to albo niemożliwe, albo bardzo trudne do uzyskania tuż przed pojawieniem się Unicode. Jest nawet nieoficjalna sekcja Klingońskiego w Unicode. Rzeczywiście, Unicode jest wystarczająco duży, aby umożliwić nieoficjalne, prywatne obszary.
ile bitów używa Unicode do zakodowania wszystkich tych znaków? Brak Ponieważ Unicode nie jest kodowaniem.
zdezorientowany? Wielu ludzi wydaje się być. Unicode definiuje przede wszystkim tabelę punktów kodowych dla znaków. To fantazyjny sposób na powiedzenie „65 oznacza A, 66 oznacza B, a 9,731 oznacza ☃” (poważnie, tak jest). Jak te Punkty kodowe są faktycznie zakodowane w bity, to inny temat. Aby reprezentować 1 114 112 różnych wartości, dwa bajty nie wystarczą. Trzy bajty są, ale trzy bajty są często niewygodne w pracy, więc cztery bajty byłyby wygodnym minimum. Ale jeśli nie używasz chińskiego lub innych znaków z dużymi liczbami, które wymagają wielu bitów do zakodowania, nigdy nie użyjesz dużej części tych czterech bajtów. Jeśli litera „A”była zawsze zakodowana na 00000000 00000000 00000000 01000001,” B”zawsze na 00000000 00000000 00000000 01000010 I tak dalej, każdy dokument byłby czterokrotnie większy od wymaganego rozmiaru.
aby to zoptymalizować, istnieje kilka sposobów kodowania punktów kodu Unicode na bity. UTF-32 jest takim kodowaniem, które koduje wszystkie punkty kodu Unicode za pomocą 32 bitów. Czyli cztery bajty na znak. To bardzo proste, ale często marnuje dużo miejsca. UTF-16 i UTF-8 to kodowania o zmiennej długości. Jeśli znak może być reprezentowany za pomocą pojedynczego bajtu (ponieważ jego punktem kodowym jest bardzo mała liczba), UTF-8 zakoduje go pojedynczym bajtem. Jeśli wymaga dwóch bajtów, użyje dwóch bajtów i tak dalej. Ma rozbudowane sposoby używania najwyższych bitów w bajcie, aby zasygnalizować, ile bajtów składa się znak. Może to zaoszczędzić miejsce, ale może również marnować miejsce, jeśli te bity sygnału muszą być często używane. UTF-16 jest w środku, używa co najmniej dwóch bajtów, rośnie do czterech bajtów w razie potrzeby.
| character | encoding | bits |
|---|---|---|
| A | UTF-8 | 01000001 |
| A | UTF-16 | 00000000 01000001 |
| A | UTF-32 | 00000000 00000000 00000000 01000001 |
| あ | UTF-8 | 11100011 10000001 10000010 |
| あ | UTF-16 | 00110000 01000010 |
| あ | UTF-32 | 00000000 00000000 00110000 01000010 |
i to wszystko. Unicode jest dużą tabelą odwzorowującą znaki na liczby, a różne kodowania UTF określają sposób kodowania tych liczb jako bitów. Ogólnie Rzecz Biorąc, Unicode jest kolejnym schematem kodowania. Nie ma w tym nic specjalnego, po prostu stara się pokryć wszystko, a jednocześnie jest skuteczny. I to dobrze.™
Punkty kodowe
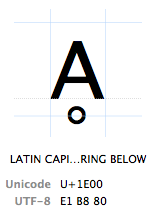
znaki są określane przez ich „punkt kodu Unicode”. Punkty kodu Unicode są zapisywane w systemie szesnastkowym (dla skrócenia liczb), poprzedzone przez „U+” (tak właśnie robią, nie ma to innego znaczenia niż „to jest punkt kodu Unicode”). Znak Ḁ ma kod Unicode punkt U+1E00. W innych (dziesiętnych) słowach jest to 7680. znak tabeli Unicode. Oficjalnie nazywa się go „łacińską wielką literą A Z pierścieniem poniżej”.
TL;DR
podsumowanie wszystkich powyższych: każdy znak może być zakodowany w wielu różnych sekwencjach bitowych, a każda konkretna Sekwencja bitowa może reprezentować wiele różnych znaków, w zależności od tego, które kodowanie jest używane do ich odczytu lub zapisu. Powodem jest po prostu to, że różne kodowania używają różnych liczb bitów na znaki i różnych wartości do reprezentowania różnych znaków.
| bits | encoding | characters |
|---|---|---|
11000100 01000010 |
Windows Latin 1 | ÄB |
11000100 01000010 |
Mac Roman | ƒB |
11000100 01000010 |
GB18030 | 腂 |
| characters | encoding | bits | 01000110 10111111 10011010 |
|---|---|---|
| føö | UTF-8 |
01000110 11000011 10111000 11000011 10110110 |
nieporozumienia, nieporozumienia i problemy
Po tym wszystkim, dochodzimy do rzeczywistych problemów doświadczanych przez wielu użytkowników i programistów każdego dnia, jak te problemy odnoszą się do wszystkich powyższych problemów i jakie jest ich rozwiązanie. Największym problemem jest:
dlaczego na Boga moje postacie są zniekształcone?!
ÉGÉìÉRÅ;Jeśli to$string było w kodowaniu jednobajtowym, dałoby nam to pierwszy znak. Ale tylko dlatego ,że” znak „pokrywa się z” bajtem ” w kodowaniu jednobajtowym. PHP po prostu daje nam pierwszy bajt bez myślenia o „znakach”. Ciągi są sekwencjami bajtowymi dla PHP, nic więcej, nic mniej. Cała ta” czytelna postać ” jest rzeczą ludzką, a PHP się tym nie przejmuje.
01000100 01101111 01101110 00100111 01110100D o n ' t01100011 01100001 01110010 01100101 00100001c a r e !to samo dotyczy wielu standardowych funkcji, takich jaksubstrstrpostrim I tak dalej. Brak wsparcia powstaje, gdy istnieje rozbieżność między długością bajtu a znakiem.
11100110 10111100 10100010 11100101 10101101 10010111漢 字
użycie$string na powyższym łańcuchu ponownie poda nam pierwszy bajt, który jest11100110. Innymi słowy, jedna trzecia trzy-bajtowego znaku „漢”. 11100110 sama w sobie jest nieprawidłową sekwencją UTF-8, więc łańcuch jest teraz zepsuty. Jeśli masz na to ochotę, możesz spróbować zinterpretować to w innym kodowaniu, gdzie 11100110 reprezentuje prawidłowy znak, co spowoduje powstanie jakiegoś losowego znaku. Baw się dobrze, ale nie używaj go w produkcji.
i to właściwie wszystko. „PHP nie obsługuje natywnie Unicode” oznacza po prostu, że większość funkcji PHP przyjmuje jeden bajt = jeden znak, co może prowadzić do przecięcia wielobajtowych znaków na pół lub nieprawidłowego obliczenia długości łańcuchów, jeśli naiwnie używasz funkcji nie-świadomych wielu bajtów na wielobajtowych łańcuchach. Nie oznacza to, że nie można używać Unicode w PHP lub że każdy ciąg Unicode musi być pobłogosławiony przez utf8_encode lub inne takie bzdury.
na szczęście istnieje rozszerzenie wielobajtowego ciągu, które replikuje wszystkie ważne funkcje ciągu w sposób świadomy wielobajtowo. Użycie mb_substr($string, 0, 1, 'UTF-8') na powyższym łańcuchu poprawnie zwraca 11100110 10111100 10100010, który jest całym znakiem „漢”. Ponieważ funkcje mb_ muszą teraz myśleć o tym, co robią, muszą wiedzieć, nad jakim kodowaniem pracują. Dlatego każda funkcjamb_ akceptuje również parametr$encoding. Alternatywnie można to ustawić globalnie dla wszystkich funkcjimb_ używającmb_internal_encoding.
używanie i nadużywanie obsługi kodowania PHP
cała kwestia (nie)wsparcia PHP dla Unicode jest taka, że po prostu nie obchodzi. Ciągi są sekwencjami bajtowymi PHP. Jakie bajty w szczególności nie mają znaczenia. PHP nie robi nic z łańcuchami oprócz przechowywania ich w pamięci. PHP po prostu nie ma żadnego pojęcia ani znaków, ani kodowania. I o ile nie próbuje manipulować łańcuchami, nie musi też tego robić; po prostu trzyma bajty, które mogą lub nie mogą być ostatecznie interpretowane jako znaki przez kogoś innego. Jedynym wymaganiem, jakie PHP ma do kodowania, jest to, że kod źródłowy PHP musi być zapisany w kodowaniu zgodnym z ASCII. Parser PHP szuka pewnych znaków, które mówią mu, co ma robić. $00100100) sygnalizuje początek zmiennej,=00111101) przypisanie,"00100010) początek i koniec łańcucha i tak dalej. Wszystko inne, co nie ma specjalnego znaczenia dla parsera, jest po prostu traktowane jako literalny ciąg bajtów. Obejmuje to wszystko między cytatami, jak omówiono powyżej. Oznacza to:
-
nie możesz zapisać kodu źródłowego PHP w kodowaniu niezgodnym z ASCII. Na przykład w UTF-16 a
"jest kodowany00000000 00100010. W PHP, które próbuje odczytać wszystko jako ASCII, jest toNULbajt, po którym następuje".PHP prawdopodobnie dostanie czkawkę, jeśli każdy inny znak, który znajdzie, toNULbajt. -
Możesz zapisać kod źródłowy PHP w dowolnym kodowaniu zgodnym z ASCII. Jeśli pierwsze 128 punktów kodowania jest zgodne z ASCII, PHP może je przeanalizować. Wszystkie znaki, które są w jakikolwiek sposób istotne dla PHP, znajdują się w 128 punktach kodowych zdefiniowanych przez ASCII. Jeśli literały łańcuchów zawierają jakiekolwiek punkty kodu poza tym, PHP nie obchodzi. Możesz zapisać kod źródłowy PHP w ISO-8859-1, Mac Roman, UTF-8 lub dowolnym innym kodowaniu zgodnym z ASCII. Literały ciągu znaków w Twoim skrypcie będą miały kodowanie, jako które zapisałeś kod źródłowy.
-
każdy plik zewnętrzny przetwarzany w PHP może być w dowolnym kodowaniu. Jeśli PHP nie musi go analizować, nie ma żadnych wymagań, które należy spełnić, aby utrzymać parser PHP zadowolony.
$foo = file_get_contents('bar.txt');powyższe po prostu odczyta bity z
bar.txtdo zmiennej$foo. PHP nie próbuje interpretować,konwertować, kodować ani w inny sposób manipulować zawartością. Plik może nawet zawierać dane binarne, takie jak obraz,PHP nie obchodzi. -
Jeśli wewnętrzne i zewnętrzne kodowania muszą się zgadzać, muszą się zgadzać. Częstym przypadkiem jest lokalizacja, gdzie kod źródłowy zawiera coś takiego jak
echo localize('Foobar'), a zewnętrzny plik lokalizacyjny zawiera coś podobnego do tego:msgid "Foobar"msgstr "フーバー"oba łańcuchy” Foobar ” muszą mieć identyczną reprezentację bitową, jeśli chcesz znaleźć poprawną lokalizację.Jeśli kod źródłowy został zapisany w ASCII, ale plik lokalizacyjny w UTF-16, ciągi znaków nie pasowałyby.Albo konieczna byłaby jakaś konwersja kodowania,albo użycie świadomej kodowania funkcji dopasowywania łańcuchów.
bystry czytelnik może w tym momencie zapytać, czy możliwe jest zapisanie, powiedzmy, sekwencji bajtów UTF-16 wewnątrz ciągu literalnego pliku kodu źródłowego zakodowanego w ASCII, na który odpowiedź brzmiałaby: absolutnie.
echo "UTF-16";Jeśli możesz przynieść swój edytor tekstu, aby zapisaćecho " I"; części w ASCII i tylkoUTF-16 w UTF-16, będzie to działać dobrze. Niezbędna do tego reprezentacja binarna wygląda następująco:
01100101 01100011 01101000 01101111 00100000 00100010e c h o "11111110 11111111 00000000 01010101 00000000 01010100(UTF-16 marker) U T00000000 01000110 00000000 00101101 00000000 00110001F - 100000000 00110110 00100010 001110116 " ;pierwsza linia i dwa ostatnie bajty są ASCII. Reszta to UTF-16 z dwoma bajtami na znak. Wiodący11111110 11111111 w linii 2 jest znacznikiem wymaganym na początku tekstu zakodowanego w UTF-16 (wymaganym przez standard UTF-16, PHP ma to gdzieś). Ten skrypt PHP szczęśliwie wyprowadzi ciąg „UTF-16” zakodowany w UTF-16, ponieważ po prostu wyprowadza bajty między dwoma podwójnymi cudzysłowami, co zdarza się reprezentować tekst „UTF-16” zakodowany w UTF-16. Plik kodu źródłowego nie jest ani w pełni poprawny, ani ASCII, ani UTF-16, więc praca z nim w edytorze tekstu nie będzie zbyt przyjemna.
Podsumowując
PHP obsługuje Unicode, a właściwie dowolne kodowanie, po prostu dobrze, o ile spełnione są pewne wymagania, aby Parser był zadowolony, a programista wiedział, co robi. Tak naprawdę wystarczy zachować ostrożność podczas manipulowania ciągami znaków, co obejmuje krojenie, przycinanie, liczenie i inne operacje, które muszą odbywać się na poziomie znaków, a nie na poziomie bajtów. Jeśli nie „robisz nic” ze swoimi ciągami poza czytaniem i wyprowadzaniem ich, nie będziesz miał problemów z obsługą kodowań PHP, których nie miałbyś również w żadnym innym języku.
języki świadome kodowania
Co to znaczy, że język obsługuje Unicode? Javascript na przykład obsługuje Unicode. W rzeczywistości każdy ciąg znaków w Javascript jest kodowany UTF-16. W rzeczywistości jest to jedyna rzecz, z którą radzi sobie Javascript. W Javascript nie można mieć napisu, który nie jest zakodowany w UTF-16. Javascript czci Unicode do tego stopnia, że nie ma możliwości radzenia sobie z jakimkolwiek innym kodowaniem w podstawowym języku. Ponieważ Javascript jest najczęściej uruchamiany w przeglądarce, która nie stanowi problemu, ponieważ przeglądarka może obsługiwać przyziemną logistykę kodowania i dekodowania wejścia i wyjścia.
inne języki są po prostu świadome kodowania. Wewnętrznie przechowują ciągi znaków w określonym kodowaniu, często UTF-16. Z kolei trzeba im powiedzieć lub spróbować wykryć kodowanie wszystkiego, co ma do czynienia z tekstem. Muszą wiedzieć, w jakim kodowaniu kod źródłowy jest zapisany, w jakim kodowaniu ma być odczytany plik, w jakim kodowaniu ma być wyświetlany tekst; i w razie potrzeby konwertują kodowanie z jakąś manifestacją Unicode jako pośrednika. Robią to samo, co możesz/powinieneś/powinnaś zrobić w PHP półautomatycznie za kulisami. To nie jest ani lepsze ani gorsze od PHP, tylko inne. Fajną rzeczą jest to, że funkcje języka standardowego, które zajmują się ciągami po prostu działają™, podczas gdy w PHP należy poświęcić trochę uwagi na to, czy łańcuch może zawierać znaki wielobajtowe, czy nie i odpowiednio wybrać funkcje manipulacji łańcuchami.
głębia Unicode
ponieważ Unicode zajmuje się wieloma różnymi skryptami i wieloma różnymi problemami, ma w sobie dużo głębi. Na przykład standard Unicode zawiera informacje dotyczące takich problemów jak unifikacja ideografów CJK. Oznacza to, że dwa lub więcej znaków chińskich / japońskich / koreańskich faktycznie reprezentują ten sam znak w nieco innych metodach pisania. Lub zasady dotyczące konwersji z małych liter na wielkie, na odwrót i w obie strony, co nie zawsze jest tak proste we wszystkich skryptach, jak w większości zachodnioeuropejskich skryptów łacińskich. Niektóre znaki mogą być również reprezentowane za pomocą różnych punktów kodowych. Litera ” ö ” może być na przykład reprezentowana za pomocą punktu kodowego U+00f6 („łacińska mała litera O Z DIAEREZĄ”) lub jako dwa punkty kodowe U+006f („łacińska mała litera O”) I U+0308 („łączący DIAEREZĘ”), czyli litera” o „połączona z””. W UTF-8 jest to sekwencja dwubajtowa 11000011 10110110 lub Sekwencja trójbajtowa 01101111 11001100 10001000, reprezentująca ten sam znak czytelny dla człowieka. W związku z tym istnieją reguły regulujące normalizację w standardzie Unicode, tj. sposób konwersji jednej z tych form na drugą. To i wiele więcej jest poza zakresem tego artykułu, ale należy być tego świadomym.
Final TL;DR
- tekst jest zawsze sekwencją bitów, która musi być przetłumaczona na tekst czytelny dla człowieka za pomocą tabel wyszukiwania. Jeśli używana jest niewłaściwa tabela wyszukiwania, używany jest niewłaściwy znak.
- nigdy nie masz do czynienia bezpośrednio z ” znakami „lub” tekstem”, zawsze masz do czynienia z bitami widzianymi przez kilka warstw abstrakcji. Nieprawidłowe wyniki są oznaką uszkodzenia jednej z warstw abstrakcji.
- jeśli dwa systemy rozmawiają ze sobą, zawsze muszą określić, w jakim kodowaniu chcą ze sobą rozmawiać. Najprostszym tego przykładem jest strona informująca przeglądarkę, że jest zakodowana w UTF-8.
- w dzisiejszych czasach standardowym kodowaniem jest UTF-8, ponieważ może kodować praktycznie każdy interesujący znak, jest wstecznie kompatybilny z podstawowym ASCII de facto i jest stosunkowo wydajny dla większości przypadków użycia.
- Inne kodowania nadal okazjonalnie mają swoje zastosowania, ale powinieneś mieć konkretny powód, aby radzić sobie z bólami głowy związanymi z zestawami znaków, które mogą kodować tylko podzbiór Unicode.
- dni jednego bajtu = jeden znak się skończyły i zarówno Programiści, jak i programy muszą nadrobić zaległości.
teraz naprawdę nie powinieneś już mieć wymówki, gdy następnym razem będziesz garble jakiegoś tekstu.
-
tak, oznacza to, że ASCII można zapisywać i przesyłać używając tylko 7 bitów i często tak jest. Nie, to nie jest w zakresie tego artykułu i dla dobra argumentu Zakładamy, że najwyższy bit jest „zmarnowany” w ASCII. ↩
-
a jeśli nie, to zostanie rozszerzona. To już było kilka razy. ↩
-
proszę zauważyć, że kiedy używam terminu „starting” wraz z „byte”, mam na myśli to z punktu widzenia czytelnego dla człowieka. ↩
-
zapoznaj się ze specyfikacją UTF-8, jeśli chcesz postępować zgodnie z tym piórem i papierem.
-
Hej, jestem programistą, nie biologiem. ↩
-
i oczywiście nie będzie ostatniego backupu. ↩
-
„znak Unicode” jest punktem kodowym w tabeli Unicode. „あ あ” nie jest znakiem Unicode, jest literą hiragana. Jest na to punkt kodu Unicode, ale to nie czyni samej litery znakiem Unicode. „Znak UTF-8 „jest oksymoronem, ale może być rozciągnięty do tego, co technicznie nazywa się” sekwencją UTF-8″, która jest sekwencją bajtów jednego, dwóch, trzech lub czterech bajtów reprezentujących jeden znak Unicode. Oba terminy są często używane w znaczeniu „każda litera, która nie jest częścią mojej klawiatury”, co oznacza absolutnie nic. David
-
http://www.php.net/manual/en/function.utf8-encode.php David
o autorze
David C. Zentgraf jest web developerem pracującym częściowo w Japonii i Europie i regularnie zajmuje się Stack Overflow.Jeśli masz opinie, krytykę lub uzupełnienia, możesz spróbować @deceze na Twitterze, zgadnąć na jego adres e-mail lub sprawdzić go za pomocą uświęconych czasem metod.Artykuł został opublikowany na kunststube.net. i nie, nie ma brudnego słowa w „Kunststube”.