ceea ce fiecare programator absolut, pozitiv trebuie să știe despre codificări și seturi de caractere pentru a lucra cu text
Dacă aveți de-a face cu text într-un computer, trebuie să știți despre codificări. Punct. Da, chiar dacă trimiteți doar e-mailuri. Chiar dacă primiți doar e-mailuri. Nu trebuie să înțelegeți fiecare ultim detaliu, dar trebuie cel puțin să știți despre ce este vorba despre toată această „codificare”. Și mai întâi vestea bună: în timp ce subiectul poate deveni dezordonat și confuz, ideea de bază este într-adevăr, foarte simplă.
Acest articol este despre codificări și seturi de caractere. Un articol de Joel Spolsky intitulat minimul absolut fiecare dezvoltator de Software absolut, pozitiv trebuie să știe despre Unicode și seturi de caractere (fără scuze!) este o introducere frumoasă a subiectului și îmi place foarte mult să îl citesc din când în când. Ezit să se refere la oameni care au probleme de înțelegere probleme de codificare, deși, deoarece, în timp ce de divertisment, este destul de lumina pe Detalii tehnice reale. Sper că acest articol poate arunca mai multă lumină asupra a ceea ce este exact o codificare și de ce tot textul dvs. se înșurubează atunci când aveți nevoie cel mai puțin. Acest articol se adresează dezvoltatorilor (cu accent pe PHP), dar orice utilizator de computer ar trebui să poată beneficia de acesta.
Noțiuni de bază direct
toată lumea este conștientă de acest lucru la un anumit nivel, dar cumva această cunoaștere pare să dispară brusc într-o discuție despre text, așa că haideți să o scoatem mai întâi: un computer nu poate stoca „litere”, „numere”, „imagini” sau orice altceva. Singurul lucru cu care poate stoca și lucra sunt biți. Un bit poate avea doar două valori: yes sau notrue sau false1 sau 0 sau orice altceva doriți să numiți aceste două valori. Deoarece un computer funcționează cu electricitate, un bit” real ” este un blip de electricitate care este sau nu există. Pentru oameni, aceasta este de obicei reprezentată folosind 1 și 0 și voi rămâne cu această convenție în acest articol.
pentru a folosi biți pentru a reprezenta orice altceva în afară de biți, avem nevoie de reguli. Trebuie să convertim o secvență de biți în ceva de genul literelor, numerelor și imaginilor folosind o schemă de codificare sau codificare pe scurt. Astfel:
01100010 01101001 01110100 01110011b i t sîn această codificare, 01100010 înseamnă litera „b”, 01101001 pentru litera „i”, 01110100 înseamnă „t” și 01110011 pentru „s”. O anumită secvență de biți reprezintă o literă și o literă reprezintă o anumită secvență de biți. Dacă puteți păstra acest lucru în cap pentru 26 de litere sau sunt foarte rapid cu căutarea chestii într-un tabel, ai putea citi biți ca o carte.
schema de codificare de mai sus se întâmplă să fie ASCII. Un șir de 1s și 0s este împărțit în părți de opt biți fiecare (un octet pe scurt). Codificarea ASCII specifică un tabel care traduce octeți în litere lizibile de om. Iată un scurt fragment din acel tabel:
| bits | character |
|---|---|
01000001 |
A |
01000010 |
B |
01000011 |
C |
01000100 |
D |
01000101 |
E |
01000110 |
F |
There are 95 human readable caracterele specificate în tabelul ASCII, inclusiv literele de la A La Z, atât în majuscule, cât și în minuscule, numerele de la 0 la 9, o mână de semne de punctuație și caractere precum simbolul dolarului, ampersand și alte câteva. De asemenea, include 33 de valori pentru lucruri precum space, line feed, tab, backspace și așa mai departe. Acestea nu sunt imprimabile în sine, dar sunt încă vizibile într-o anumită formă și utile direct oamenilor. Un număr de valori sunt utile numai pentru un computer, cum ar fi codurile pentru a semnifica începutul sau sfârșitul unui text. În total, există 128 de caractere definite în codificarea ASCII, care este un număr rotund frumos (pentru persoanele care se ocupă de computere), deoarece folosește toate combinațiile posibile de 7 biți (000000000000010000010 prin 1111111).1
și iată-l, modul de a reprezenta textul care poate fi citit de om folosind doar1s și0s.
01001000 01100101 01101100 01101100 01101111 00100000 01010111 01101111 01110010 01101100 01100100„Hello World”
termeni importanți
pentru a codifica ceva în ASCII, urmați tabelul de la dreapta la stânga, înlocuind literele pentru biți. Pentru a decoda un șir de biți în caractere lizibile de om, urmați tabelul de la stânga la dreapta, înlocuind biții cu litere.
encode|en inktifk inktifd/
verb
convertește într-o formă codificatăCod|k inktifd /
substantiv
un sistem de cuvinte, litere, cifre sau alte simboluri substituite cu alte cuvinte, litere etc.
a codifica înseamnă a folosi ceva pentru a reprezenta altceva. O codificare este setul de reguli cu care să convertiți ceva de la o reprezentare la alta.
alți termeni care merită clarificați în acest context:
set de caractere, set de caractere setul de caractere care pot fi codificate. „Codificarea ASCII cuprinde un set de caractere de 128 de caractere.”În esență sinonim cu „codificare”. pagina de cod o” pagină ” de coduri care mapează un caracter la un număr sau o secvență de biți. Alias „masa”. În esență sinonim cu „codificare”. string un șir este o grămadă de elemente înșirate împreună. Un șir de biți este o grămadă de biți, cum ar fi01010011
. Un șir de caractere este o grămadă de caractere,like this. Sinonim cu „secvență”.
binar, octal, zecimal, hex
există multe moduri de a scrie numere. 10011111 în binar este 237 în octal este 159 în zecimal este 9f în hexazecimal. Toate reprezintă aceeași valoare, dar hexazecimal este mai scurt și mai ușor de citit decât binar. Voi lipi cu binar de-a lungul acestui articol pentru a obține punctul de peste mai bine și de rezervă cititorul un strat de abstractizare. Nu vă alarmați să vedeți codurile de caractere menționate în alte notații în altă parte, este același lucru.
Scuzati-ma?
acum că știm despre ce vorbim, să spunem doar: 95 de caractere nu sunt prea multe când vine vorba de limbi. Acesta acoperă elementele de bază ale limbii engleze, dar ceea ce despre scris o scrisoare risqu în limba franceză? O straine de la un sfert de secol la un sfert de secol la un sfert de secol în limba germană? O invitație la un SM untricrg unktsbord în Suedeză? Ei bine, nu ai putea. nu în ASCII. Nu există nici o specificatie cu privire la modul de a reprezenta oricare dintre literele n, β, ü, ä, ö å sau în ASCII, deci nu le poți folosi.
„dar uitați-vă”, au spus europenii,”într-un computer obișnuit cu 8 biți la octet, ASCII pierde un întreg bit care este întotdeauna setat la 0! Putem folosi acest bit pentru a stoarce un întreg ‘ nother 128 valori în acel tabel!”Și așa au făcut. Dar chiar și așa, există mai mult de 128 de moduri de a mângâia, tăia, tăia și pune o vocală. Nu toate variațiile de Litere și squiggles utilizate în toate limbile europene pot fi reprezentate în același tabel cu maximum 256 de valori. Deci, ceea ce a ajuns lumea este o multitudine de scheme de codificare, standarde, standarde de facto și jumătăți de standarde care acoperă toate un subset diferit de caractere. Cineva trebuia să scrie un document despre suedeză în cehă, a constatat că nicio codificare nu acoperea ambele limbi și a inventat una. Sau așa îmi imaginez că a trecut de nenumărate ori.și să nu uităm despre Rusă, Hindi, arabă, ebraică, coreeană și toate celelalte limbi în prezent în uz activ pe această planetă. Ca să nu mai vorbim de cele care nu mai sunt folosite. După ce ați rezolvat problema modului de a scrie documente lingvistice mixte în toate aceste limbi, încercați-vă pe Chineză. Sau Japoneză. Ambele conțin zeci de mii de caractere. Ai 256 valori posibile la un octet format din 8 biți. Du-te!
codificări Multi-octet
pentru a crea un tabel care mapează caractere la Litere pentru o limbă care utilizează mai mult de 256 de caractere, un octet pur și simplu nu este suficient. Folosind doi octeți (16 biți), este posibil să codificați 65.536 de valori distincte. BIG-5 este o codificare atât de dublă. În loc să rupă un șir de biți în blocuri de opt, îl rupe în blocuri de 16 și are un tabel mare (adică mare) care specifică la ce caracter se mapează fiecare combinație de biți. BIG-5 în forma sa de bază acoperă în mare parte caractere tradiționale chinezești. GB18030 este o altă codificare care face în esență același lucru, dar include atât caractere tradiționale, cât și caractere chinezești simplificate. Și înainte de a întreba, da, există codificări care acoperă doar Chineza simplificată. Nu putem avea doar o codificare acum, nu-i așa?
aici un mic fragment din tabelul GB18030:
| bits | character |
|---|---|
10000001 01000000 |
丂 |
10000001 01000001 |
丄 |
10000001 01000010 |
丅 |
10000001 01000011 |
丆 |
10000001 01000100 |
丏 |
GB18030 covers quite a range of characters (including a large part of latin caractere), dar în cele din urmă este încă un alt format de codificare specializat printre mulți.
Unicode la confuzia

În cele din urmă cineva a avut destul de mizerie și a stabilit pentru a crea un inel pentru a le lega toate crea o codificare standard pentru a unifica toate standardele de codificare. Acest standard este Unicode. Practic definește un tabel ginorm de 1.114.112 puncte de cod care pot fi folosite pentru tot felul de Litere și simboluri. Asta e o multime de a codifica toate europene, Orientul Mijlociu, Orientul Îndepărtat, Sud, Nord, Vest, pre-istoric și personaje viitoare omenirea știe despre.2 Folosind Unicode, puteți scrie un document care conține practic orice limbă folosind orice caracter pe care îl puteți introduce într-un computer. Acest lucru a fost fie imposibil, fie foarte greu de obținut chiar înainte ca Unicode să apară. Există chiar și o secțiune neoficială pentru klingonieni în Unicode. Într-adevăr, Unicode este suficient de mare pentru a permite zone neoficiale, cu utilizare privată.deci, câți biți folosește Unicode pentru a codifica toate aceste caractere? Niciuna. Deoarece Unicode nu este o codificare.
confuz? Mulți oameni par să fie. Unicode definește în primul rând un tabel de puncte de cod pentru caractere. Acesta este un mod fantezist de a spune că „65 înseamnă A, 66 înseamnă B și 9.731 înseamnă centimetrul” (serios, înseamnă). Modul în care aceste puncte de cod sunt de fapt codificate în biți este un subiect diferit. Pentru a reprezenta 1.114.112 valori diferite, doi octeți nu sunt suficienți. Trei octeți sunt, dar trei octeți sunt adesea incomode de lucrat, deci patru octeți ar fi minimul confortabil. Dar, cu excepția cazului în care utilizați de fapt chineză sau unele dintre celelalte caractere cu numere mari care necesită o mulțime de biți pentru a codifica, nu veți folosi niciodată o bucată uriașă din cei patru octeți. Dacă litera”A”a fost întotdeauna codificată la 00000000 00000000 00000000 01000001,”B”întotdeauna la 00000000 00000000 00000000 01000010 și așa mai departe, orice document s-ar umfla de patru ori dimensiunea necesară.
pentru a optimiza acest lucru, există mai multe moduri de a codifica punctele de cod Unicode în biți. UTF-32 este o astfel de codificare care codifică toate punctele de cod Unicode folosind 32 de biți. Adică patru octeți pe caracter. Este foarte simplu, dar deseori pierde mult spațiu. UTF-16 și UTF-8 sunt codificări de lungime variabilă. Dacă un caracter poate fi reprezentat folosind un singur octet (deoarece punctul său de cod este un număr foarte mic), UTF-8 îl va codifica cu un singur octet. Dacă necesită doi octeți, va folosi doi octeți și așa mai departe. Are modalități elaborate de a utiliza cei mai mari biți dintr-un octet pentru a semnala din câți octeți constă un caracter. Acest lucru poate economisi spațiu, dar poate pierde și spațiu dacă acești biți de semnal trebuie folosiți des. UTF – 16 este în mijloc, folosind cel puțin doi octeți, crescând până la patru octeți, după cum este necesar.
| character | encoding | bits |
|---|---|---|
| A | UTF-8 | 01000001 |
| A | UTF-16 | 00000000 01000001 |
| A | UTF-32 | 00000000 00000000 00000000 01000001 |
| あ | UTF-8 | 11100011 10000001 10000010 |
| あ | UTF-16 | 00110000 01000010 |
| あ | UTF-32 | 00000000 00000000 00110000 01000010 |
și asta e tot ce este de făcut. Unicode este un tabel mare de caractere de cartografiere la numere și diferitele codificări UTF specifica modul în care aceste numere sunt codificate ca biți. În general, Unicode este încă o altă schemă de codificare. Nu este nimic special în asta, încearcă doar să acopere totul în timp ce este încă eficient. Și ăsta e un lucru bun.
puncte de cod
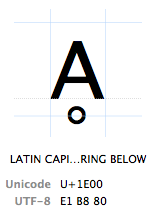
caracterele sunt menționate prin „punctul lor de cod Unicode”. Punctele de cod Unicode sunt scrise în hexazecimal (pentru a menține numerele mai scurte), precedate de un „U+” (exact ceea ce fac, nu are altă semnificație decât „acesta este un punct de cod Unicode”). Caracterul de la punctul de cod Unicode U+1e00. În alte cuvinte (zecimale), este caracterul 7680 al tabelului Unicode. Se numește oficial”majusculă latină A cu inel de mai jos”.
TL;DR
Un rezumat al tuturor celor de mai sus: orice caracter poate fi codificat în multe secvențe de biți diferite și orice secvență de biți particulară poate reprezenta multe caractere diferite, în funcție de codificarea utilizată pentru a le citi sau scrie. Motivul este pur și simplu pentru că diferite codificări folosesc numere diferite de biți pe caractere și valori diferite pentru a reprezenta caractere diferite.
| bits | encoding | characters |
|---|---|---|
11000100 01000010 |
Windows Latin 1 | ÄB |
11000100 01000010 |
Mac Roman | ƒB |
11000100 01000010 |
GB18030 | 腂 |
| characters | encoding | bits |
|---|---|---|
| f | Windows Latin 1 | 01000110 11111000 11110110 |
| f td> | 01000110 10111111 10011010 |
|
| f-8 | 01000110 11000011 10111000 11000011 10110110 |
concepții greșite, confuzii și probleme
acestea fiind spuse, ajungem la problemele reale cu care se confruntă mulți utilizatori și programatori în fiecare zi, cum se raportează aceste probleme la toate cele de mai sus și care este soluția lor. Cea mai mare problemă dintre toate este:
de ce, în numele lui Dumnezeu, personajele mele sunt deformate?!
ÉGÉìÉRÅ;dacă$string ar fi într-o codificare cu un singur octet, acest lucru ne-ar da primul caracter. Dar numai pentru că” caracter „coincide cu” octet ” într-o codificare cu un singur octet. PHP ne oferă pur și simplu primul octet fără să ne gândim la „personaje”. Șirurile sunt secvențe de octeți în PHP, nimic mai mult, nimic mai puțin. Toate aceste lucruri „caracter lizibil” sunt un lucru uman și PHP nu-i pasă de asta.
01000100 01101111 01101110 00100111 01110100D o n ' t01100011 01100001 01110010 01100101 00100001c a r e !același lucru este valabil pentru multe funcții standard, cum ar fisubstrstrpostrim și așa mai departe. Non-suport apare dacă există o discrepanță între lungimea unui octet și un caracter.
11100110 10111100 10100010 11100101 10101101 10010111漢 字
folosind$string pe șirul de mai sus ne va da, din nou, primul octet, care este11100110. Cu alte cuvinte, o treime din caracterul de trei octeți „XV”. 11100110 este, de la sine, o secvență nevalidă UTF-8, deci șirul este acum rupt. Dacă ați simțit acest lucru, ați putea încerca să interpretați acest lucru într-o altă codificare în care 11100110 reprezintă un caracter valid, ceea ce va duce la un caracter aleatoriu. Distrează-te, dar nu-l folosi în producție.
și asta este de fapt tot ce există. „PHP nu acceptă nativ Unicode” înseamnă pur și simplu că majoritatea funcțiilor PHP își asumă un octet = un caracter, ceea ce poate duce la tăierea caracterelor multi-octet în jumătate sau calcularea incorectă a lungimii șirurilor dacă utilizați naiv funcții care nu sunt conștiente de mai mulți octeți pe șiruri de mai mulți octeți. Aceasta nu înseamnă că nu puteți utiliza Unicode în PHP sau că fiecare șir Unicode trebuie să fie binecuvântat de utf8_encode sau alte astfel de prostii.
Din fericire, există extensia șir Multibyte, care reproduce toate funcțiile șir importante într-un mod conștient multi-octet. Folosind mb_substr($string, 0, 1, 'UTF-8') pe șirul de mai sus se returnează corect 11100110 10111100 10100010, care este întregul caracter” Irak”. Deoarecemb_ funcțiile trebuie acum să se gândească efectiv la ceea ce fac, trebuie să știe la ce codificare lucrează. Prin urmare, fiecare mb_ funcție acceptă un $encoding parametru, de asemenea. Alternativ, acest lucru poate fi setat la nivel global pentru toate mb_ funcții folosind mb_internal_encoding.
utilizarea și abuzul de manipulare PHP de codificări
întreaga problemă a PHP (non-)suport pentru Unicode este că pur și simplu nu-i pasă. Șirurile sunt secvențe de octeți în PHP. Ce octeți în special nu contează. PHP nu face nimic cu siruri de caractere, cu excepția menținându-le stocate în memorie. PHP pur și simplu nu are nici un concept de caractere sau codificări. Și dacă nu încearcă să manipuleze siruri de caractere, ea nu are nevoie să fie; ea deține doar pe octeți care pot sau nu pot fi în cele din urmă interpretate ca caractere de altcineva. Singura cerință PHP are de codificări este că codul sursă PHP trebuie să fie salvate într-o codificare compatibil ASCII. Parserul PHP caută anumite caractere care îi spun ce să facă. $00100100) semnalează începutul unei variabile,=00111101) o atribuire,"00100010) începutul și sfârșitul unui șir și așa mai departe. Orice altceva care nu are nicio semnificație specială pentru parser este luat doar ca o secvență literală de octeți. Aceasta include orice între citate, așa cum sa discutat mai sus. Aceasta înseamnă următoarele:
-
nu puteți salva codul sursă PHP într-o codificare incompatibilă cu ASCII. De exemplu, în UTF-16 un
"este codificat ca00000000 00100010. Pentru PHP, care încearcă să citească totul ca ASCII, acesta este unNULoctet urmat de un".PHP va primi probabil un sughiț dacă orice alt caracter pe care îl găsește este unNULoctet. -
puteți salva codul sursă PHP în orice codificare compatibilă cu ASCII. Dacă primele 128 de puncte de cod ale unei codificări suntidentice cu ASCII, PHP o poate analiza. Toate caracterele care sunt în vreun fel semnificative pentru PHP se încadrează în cele 128 de puncte de cod definite de ASCII. Dacă literalele șirurilor conțin puncte de cod dincolo de asta, PHP nu-i pasă. Puteți salva codul sursă PHP în ISO-8859-1, Mac Roman, UTF-8 sau orice altă codificare compatibilă cu ASCII. Literalii șir în script-ul willhave orice codificare ați salvat codul sursă ca.
-
orice fișier extern pe care îl procesați cu PHP poate fi în orice codare doriți. Dacă PHP nu are nevoie să o analizeze, nu există cerințe de îndeplinit pentru a menține parserul PHP fericit.
$foo = file_get_contents('bar.txt');cele de mai sus vor citi pur și simplu biții din
bar.txtîn variabila$foo. PHP nu încearcă să interpreteze, să convertească, să codifice sau să se joace în alt mod cu conținutul. Fișierul poate conține chiar date binare, cum ar fi o imagine,PHP nu-i pasă. -
dacă codificările interne și externe trebuie să se potrivească, trebuie să se potrivească. Un caz comun este localizarea, undecodul sursă conține ceva de genul
echo localize('Foobar')și un fișier de localizare extern conțineceva de-a lungul acestei linii:msgid "Foobar"msgstr "フーバー"ambele șiruri „Foobar” trebuie să aibă o reprezentare de biți identică dacă doriți să găsiți localizarea corectă.Dacă codul sursă a fost salvat în ASCII, dar fișierul de localizare în UTF-16, șirurile nu s-ar potrivi.Fie un fel de conversie de codificare ar fi necesar, fie utilizarea unei funcții de potrivire a șirurilor conștiente de codificare.
cititorul inteligent ar putea întreba în acest moment dacă este posibil să salvați o secvență de octeți UTF-16 în interiorul unui șir literal al unui fișier cod sursă codificat ASCII, la care răspunsul ar fi: absolut.
echo "UTF-16";dacă puteți aduce editorul de text pentru a salvaecho "și";părți în ASCII și numaiUTF-16 în UTF-16, Acest lucru va funcționa foarte bine. Reprezentarea binară necesară pentru asta arată astfel:
01100101 01100011 01101000 01101111 00100000 00100010e c h o "11111110 11111111 00000000 01010101 00000000 01010100(UTF-16 marker) U T00000000 01000110 00000000 00101101 00000000 00110001F - 100000000 00110110 00100010 001110116 " ;prima linie și ultimii doi octeți sunt ASCII. Restul este UTF-16 cu doi octeți pe caracter. Liderul 11111110 11111111 pe linia 2 este un marker necesar la începutul textului codificat UTF-16 (cerut de standardul UTF-16, PHP nu dă doi bani). Acest script PHP va afișa fericit șirul ” UTF-16 „codificat în UTF-16, deoarece emite simplu octeții între cele două ghilimele duble, ceea ce se întâmplă să reprezinte textul” UTF-16 ” codificat în UTF-16. Fișierul de cod sursă nu este nici complet valabil ASCII, nici UTF-16, deci lucrul cu acesta într-un editor de text nu va fi prea distractiv.
Bottom line
PHP suporta Unicode, sau, de fapt, orice codificare, foarte bine, atâta timp cât anumite cerințe sunt îndeplinite pentru a menține parser fericit și programator știe ce face. Într-adevăr trebuie doar să fii atent atunci când manipulezi șiruri, care include felierea, tăierea, numărarea și alte operații care trebuie să se întâmple la un nivel de caracter, mai degrabă decât la un nivel de octet. Dacă nu „faci nimic” cu șirurile tale în afară de a le citi și a le scoate, cu greu vei avea probleme cu suportul PHP pentru codificări pe care nu le-ai avea și în altă limbă.
limbaje conștiente de codificare
ce înseamnă pentru o limbă să accepte Unicode atunci? Javascript, de exemplu, acceptă Unicode. De fapt, orice șir din Javascript este codificat UTF-16. De fapt, este singurul lucru cu care se ocupă Javascript. Nu puteți avea un șir în Javascript care nu este codificat UTF-16. Javascript se închină Unicode în măsura în care nu există nici o facilitate de a face cu orice altă codificare în limba de bază. Deoarece Javascript este cel mai adesea rulat într-un browser, aceasta nu este o problemă, deoarece browserul poate gestiona logistica banală a codării și decodării intrărilor și ieșirilor.
alte limbi sunt pur și simplu codificate. Intern stochează șiruri într-o anumită codificare, adesea UTF-16. La rândul lor, trebuie să li se spună sau să încerce să detecteze codificarea a tot ceea ce are legătură cu textul. Ei trebuie să știe în ce codare este salvat codul sursă, în ce codare trebuie să citească un fișier, în ce codificare doriți să trimiteți text; și convertesc codificările din mers, după cum este necesar, cu o manifestare a Unicode ca intermediar. Ei fac același lucru pe care îl puteți/ar trebui/trebuie să faceți în PHP semi-automat în spatele scenei. Asta nu e nici mai bine, nici mai rău decât PHP, doar diferit. Lucrul frumos este că funcțiile de limbaj standard care se ocupă de șiruri funcționează doar la sută, în timp ce în PHP trebuie să se acorde o atenție dacă un șir poate conține caractere multi-octet sau nu și să aleagă funcțiile de manipulare a șirurilor în consecință.
adâncimile Unicode
deoarece Unicode se ocupă cu multe scripturi diferite și multe probleme diferite, are multă profunzime. De exemplu, standardul Unicode conține informații pentru probleme precum unificarea ideografiei CJK. Asta înseamnă, informații că două sau mai multe caractere chinezești/japoneze/coreene reprezintă de fapt același caracter în metode de scriere ușor diferite. Sau reguli despre conversia de la litere mici la majuscule, invers și dus-întors, care nu este întotdeauna la fel de drept înainte în toate scripturile, așa cum este în majoritatea scripturilor derivate din latina din Europa de vest. Unele caractere pot fi, de asemenea, reprezentate folosind diferite puncte de cod. De exemplu, litera „XV” poate fi reprezentată folosind punctul de cod U+00F6 („litera mică latină O cu DIAERESIS”) sau ca cele două puncte de cod U+006f („litera mică latină O”) și U+0308 („combinarea DIAERESIS”), adică litera „o” combinată cu „”. În UTF-8 aceasta este fie secvența de doi octeți11000011 10110110, fie secvența de trei octeți01101111 11001100 10001000, ambele reprezentând același caracter lizibil uman. Ca atare, există reguli care reglementează normalizarea în cadrul standardului Unicode, adică modul în care oricare dintre aceste forme poate fi transformată în cealaltă. Acest lucru și mult mai mult este în afara domeniului de aplicare al acestui articol, dar ar trebui să fie conștienți de ea.
Final TL;DR
- textul este întotdeauna o secvență de biți care trebuie tradusă în text lizibil uman folosind tabele de căutare. Dacă se utilizează tabelul de căutare greșit, se utilizează caracterul greșit.
- nu ai de-a face niciodată direct cu „caractere” sau „text”, ai de-a face întotdeauna cu biți așa cum se vede prin mai multe straturi de abstracții. Rezultatele incorecte sunt un semn al eșecului unuia dintre straturile de abstractizare.
- dacă două sisteme vorbesc între ele, trebuie întotdeauna să specifice în ce codificare vor să vorbească între ele. Cel mai simplu exemplu în acest sens este acest site web care spune browserului dvs. că este codificat în UTF-8.
- în această zi și vârstă, codificarea standard este UTF-8, deoarece poate codifica practic orice caracter de interes, este compatibil cu linia de bază de facto ASCII și este relativ eficient din punct de vedere spațial pentru majoritatea cazurilor de utilizare.
- alte codificări au încă ocazional utilizările lor, dar ar trebui să aveți un motiv concret pentru care doriți să faceți față durerilor de cap asociate seturilor de caractere care pot codifica doar un subset de Unicode.
- zilele unui octet = un caracter s-au terminat și atât programatorii, cât și programele trebuie să recupereze acest lucru.
acum ar trebui să aveți într-adevăr nici o scuză mai Data viitoare când garble unele text.
-
da, asta înseamnă că ASCII pot fi stocate și transferate folosind doar 7 biți și de multe ori este. Nu, acest lucru nu se încadrează în domeniul de aplicare al acestui articol și, de dragul argumentului, vom presupune că cel mai mare bit este „irosit” în ASCII.
-
și dacă nu este, va fi extins. A fost deja de mai multe ori.
-
vă rugăm să rețineți că atunci când folosesc termenul „pornire” împreună cu „octet”, mă refer la acesta din punct de vedere lizibil de om.
-
citiți cu atenție specificația UTF-8 dacă doriți să urmați acest lucru cu pix și hârtie.
-
Hei, eu sunt un programator, nu un biolog.
-
și, desigur, nu va fi nici o copie de rezervă recentă. un „caracter Unicode” este un punct de cod din tabelul Unicode. „XV” nu este un personaj Unicode, este litera hiragana „x”. Există un punct de cod Unicode pentru aceasta, dar asta nu face litera în sine un caracter Unicode. Un ” caracter UTF-8 „este un oximoron, dar poate fi întins pentru a însemna ceea ce se numește tehnic” secvență UTF-8″, care este o secvență de octeți de unu, doi, trei sau patru octeți reprezentând un caracter Unicode. Ambii termeni sunt adesea folosiți în sensul „oricărei litere care nu face parte din tastatura mea”, ceea ce nu înseamnă absolut nimic.
-
http://www.php.net/manual/en/function.utf8-encode.php
despre autor
David C. Zentgraf este un dezvoltator web care lucrează parțial în Japonia și Europa și isa regulat pe preaplin stivă.Dacă aveți feedback, critici sau completări, vă rugăm să nu ezitați să încercați @deceze pe Twitter,să faceți o presupunere educată la adresa sa de e-mail sau să o căutați folosind metode onorate în timp.Acest articol a fost publicat pe kunststube.net. și nu, nu există niciun cuvânt murdar în „Kunststube”.