kdnuggets
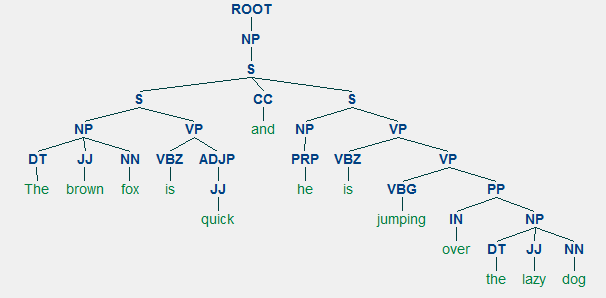
missä tahansa kielessä syntaksi ja rakenne kulkevat yleensä käsi kädessä, jossa tietyt säännöt, konventiot ja periaatteet säätelevät tapaa, jolla sanat yhdistetään lauseiksi; lauseet yhdistetään lauseiksi; ja lauseet yhdistetään lauseiksi. Puhumme erityisesti englannin kielen syntaksista ja rakenteesta tässä osiossa. Englannin kielessä sanat yleensä yhdistyvät toisiksi perusyksiköiksi. Näitä rakenneosia ovat sanat, lauseet, lauseet ja lauseet. Kun ajatellaan lausetta, ”ruskea kettu on nopea ja hän hyppää laiskan koiran yli”, se on tehty sanasarjasta ja pelkkä sanojen katsominen itsessään ei kerro paljon.

joukko järjestämättömiä sanoja ei välitä paljoakaan tietoa
tieto kielen rakenteesta ja syntaksista on hyödyllinen monilla aloilla, kuten tekstinkäsittelyssä, huomautusten antamisessa ja jäsentämisessä jatkotoimissa, kuten tekstin luokittelussa tai tiivistämisessä. Tyypillisiä jäsennystekniikoita tekstin syntaksin ymmärtämiseksi on mainittu alla.
- puheen (POS) merkintöjen osat
- Matala jäsennys tai Chunking
- vaalipiirin jäsennys
- riippuvuuden jäsennys
tarkastelemme kaikkia näitä tekniikoita myöhemmissä jaksoissa. Kun otetaan huomioon edellinen esimerkkilauseemme ”ruskea kettu on nopea ja hän hyppää laiskan koiran yli”, jos me merkitsisimme sitä käyttämällä peruspos-tunnisteita, se näyttäisi seuraavalta kuviolta.

POS-merkintä lauseelle
näin lause seuraa tyypillisesti hierarkkista rakennetta, joka koostuu seuraavista osista,
lause → lausekkeet → lausekkeet → Sanat
puheen merkitysosat
puheen osat (POS) ovat erityisiä sanastoluokkia, joihin sanat osoitetaan niiden syntaktisen kontekstin ja roolin perusteella. Yleensä sanat voivat jakautua johonkin seuraavista pääluokista.
- N (oun: Tämä tarkoittaa yleensä sanoja, jotka kuvaavat jotakin esinettä tai kokonaisuutta, joka voi olla elävä tai eloton. Joitakin esimerkkejä olisivat kettu , koira , kirja ja niin edelleen. Substantiivien POS-tunnus on N.
- V(erb): verbit ovat sanoja, joita käytetään kuvaamaan tiettyjä toimintoja, tiloja tai esiintymiä. On olemassa monenlaisia muita alaluokkia, kuten apuverbit, refleksiiviset ja transitiiviset verbit (ja monet muut). Tyypillisiä esimerkkejä verbeistä ovat juokseminen , hyppiminen , lukeminen ja kirjoittaminen . Verbien POS-tunnus on V.
- Adj (ektive: Adjektiivit ovat sanoja, joita käytetään kuvaamaan tai määrittelemään muita sanoja, tyypillisesti substantiiveja ja substantiivilausekkeita. Lauseessa kaunis kukka on substantiivi (N) kukka, joka kuvataan tai kvalifioidaan käyttämällä adjektiivia (ADJ) kaunis . Adjektiivien POS-tunnus on ADJ .
- Adv(erb): Adverbit toimivat yleensä muuntajina muille sanoille, kuten substantiiveille, adjektiiveille, verbeille tai muille adverbeille. Lauseessa hyvin kaunis kukka on adverbi (ADV) hyvin , joka muuttaa adjektiivia (ADJ) kaunis , mikä osoittaa missä määrin kukka on kaunis. Adverbien POS-tunniste on ADV.
näiden neljän puheen pääosien kategorian lisäksi on muitakin kategorioita , jotka esiintyvät usein englannin kielessä. Näitä ovat pronominit, prepositiot, interjektiot, konjunktiot, determinoijat ja monet muut. Lisäksi jokainen POS-tunniste, kuten substantiivi (n), voidaan edelleen jakaa luokkiin, kuten yksikössä olevat substantiivit (NN), yksikössä olevat erisnimet(NNP) ja monikossa olevat substantiivit (NNS).
process of classifying and labelling POS tags for words called parts of speech tagging tai POS tagging . POS-tageja käytetään sanojen merkitsemiseen ja niiden kuvaamiseen, mikä on todella hyödyllistä tiettyjen analyysien suorittamiseen, kuten substantiivien kaventamiseen ja sen näkemiseen, mitkä ovat näkyvimpiä, sananaistin disambiguaatio ja kieliopin analyysi. Hyödynnämme sekä nltk että spacy, jotka käyttävät yleensä Penn Treebank-merkintää POS-merkintänä.
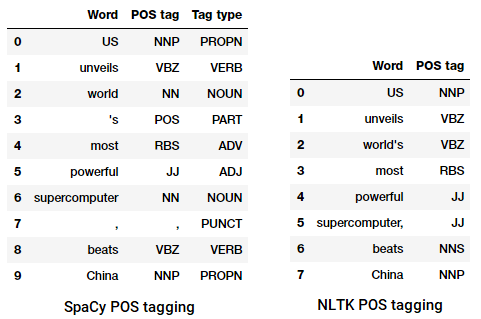
POS tagging a news headline
voimme nähdä, että jokainen näistä kirjastoista käsittelee tokeneita omalla tavallaan ja antaa niille erityisiä tägejä. Näkemämme perusteella spacy näyttää pärjäävän hieman paremmin kuin nltk.
matalat Jäsennykset tai Chunking
aiemmin kuvaamamme hierarkian perusteella sanaryhmät muodostavat lauseita. Lausekkeita on viisi pääluokkaa:
- Substantiivilauseke (NP: Nämä ovat lauseita, joissa substantiivi toimii pääsanana. Substantiivilausekkeet toimivat verbin subjektina tai objektina.
- Verbilauseke (VP): nämä lauseet ovat leksikaalisia yksiköitä, joiden pääsanana toimii verbi. Yleensä verbilausekkeita on kahta muotoa. Yhdessä muodossa on verbin osat sekä muut entiteetit, kuten substantiivit, adjektiivit tai adverbit objektin osina.
- Adjektiivilauseke (ADJP): nämä ovat lauseita, joiden pääsanana on adjektiivi. Niiden päätehtävä on kuvata tai pätevöittää substantiiveja ja pronomineja lauseessa, ja ne sijoitetaan joko substantiivin tai pronominin eteen tai jälkeen.
- Adverbilauseke (ADVP): nämä lauseet toimivat adverbien tavoin, sillä adverbi toimii lauseen pääsanana. Adverbilausekkeita käytetään substantiivien, verbien tai itse adverbien modifioijina antamalla tarkempia yksityiskohtia, jotka kuvaavat tai määrittelevät niitä.
- Prepositiolause (PP): näissä lauseissa on yleensä prepositio pääsanana ja muita leksikaalisia komponentteja, kuten substantiiveja, pronomineja ja niin edelleen. Nämä toimivat adjektiivin tai adverbin tavoin, joka kuvaa muita sanoja tai lauseita.
Matala jäsennys, tunnetaan myös nimellä kevyt jäsennys tai chunking, on suosittu luonnollisen kielen käsittelytekniikka, jossa lauseen rakennetta analysoidaan sen pienimpiin rakenneosiin (jotka ovat tokeneita, kuten sanoja) ja ryhmitellään ne yhteen korkeamman tason lauseiksi. Tämä sisältää POS-tunnisteet sekä lauseita lauseesta.
esimerkki matalasta jäsennyksestä, joka kuvaa korkeamman tason fraasihuomautuksia
hyödynnämme conll2000 corpusta, jolla koulutamme matalaa jäsennysmalliamme. Tämä corpus on saatavilla nltk chunk-merkinnöillä ja tulemme käyttämään noin 10K-tietueita mallimme kouluttamiseen. Otokseen liitetty lause on kuvattu seuraavasti.
10900 48(S Chancellor/NNP (PP of/IN) (NP the/DT Exchequer/NNP) (NP Nigel/NNP Lawson/NNP) (NP 's/POS restated/VBN commitment/NN) (PP to/TO) (NP a/DT firm/NN monetary/JJ policy/NN) (VP has/VBZ helped/VBN to/TO prevent/VB) (NP a/DT freefall/NN) (PP in/IN) (NP sterling/NN) (PP over/IN) (NP the/DT past/JJ week/NN) ./.)
edeltävästä tuotoksesta näkee, että datapisteemme ovat lauseita, joihin on jo liitetty lauseita ja POS-tageja metatietoja, joista on hyötyä matalan jäsennysmallimme koulutuksessa. Me hyödyntää kaksi chunking hyödyllisyys toimintoja, tree2conlltags, saada triplettejä word, tag, ja chunk tageja kunkin token, ja conlltags2tree tuottaa jäsentävä puu näistä token triplettejä. Käytämme näitä toimintoja kouluttaa jäsennin. Näyte on kuvattu alla.
lohkotageissa käytetään IOB-muotoa. Tämä merkintä edustaa sisällä, ulkopuolella ja alussa. B-etuliite ennen tagia osoittaa, että se on palan alku, ja I – etuliite osoittaa, että se on palan sisällä. O-merkki osoittaa, että poletti ei kuulu millekään möhkäleelle. B-tagia käytetään aina, kun sitä seuraavat samantyyppiset tunnisteet ilman, että niiden välissä on O-tageja.
määrittelemme nyt funktion conll_tag_ chunks() ottaaksemme POS-ja chunk-tunnisteita lauseista, joissa on chunked-merkintä, ja funktion combined_taggers() kouluttaaksemme useita taggereita backoff-taggereilla (esim.unigram-ja bigram-taggereilla)
määrittelemme nyt luokan NGramTagChunker, joka ottaa taggatut lauseet harjoitussyötöksi, saa niiden (word, POS Tag, chunk Tag) WTC-triplat ja kouluttaa BigramTagger kanssa UnigramTagger backoff-tagaajana. Määrittelemme myös parse() funktion, jolla voidaan suorittaa matalia jäsennyksiä uusilla lauseilla
UnigramTaggerBigramTagger, jaTrigramTaggerovat luokkia, jotka perivät perusluokastaNGramTagger, joka itse periiContextTaggerluokan, joka periiSequentialBackoffTaggerluokan.
käytämme tätä luokkaa harjoittelemaan conll2000 chunked train_data ja arvioimaan mallin suorituskykyä test_data
ChunkParse score: IOB Accuracy: 90.0%% Precision: 82.1%% Recall: 86.3%% F-Measure: 84.1%%
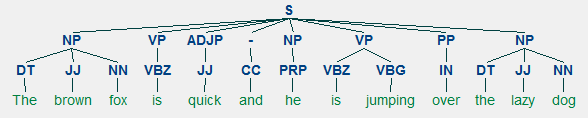
chunking-mallimme saa noin 90 prosentin tarkkuuden, mikä on melko hyvä! Nyt hyödyntää tätä mallia matala jäsentää ja chunk meidän näyte uutisartikkelin otsikko, jota käytimme aiemmin, ”US unveils maailman tehokkain supertietokone, beats China”.
chunk_tree = ntc.parse(nltk_pos_tagged)print(chunk_tree)
Output:-------(S (NP US/NNP) (VP unveils/VBZ world's/VBZ) (NP most/RBS powerful/JJ supercomputer,/JJ beats/NNS China/NNP))
näin voit nähdä, että se on tunnistanut uutisartikkelista kaksi substantiivilauseketta (np) ja yhden verbilausekkeen (VP). Jokaisen sanan POS-tunnisteet ovat myös näkyvissä. Voimme myös kuvitella tämän puun muodossa seuraavasti. Saatat joutua asentamaan Ghostscriptin, jos nltk heittää virheen.

Shallow parsed news headline
edeltävä tuotos antaa hyvän rakenteen tunteen matalien uutisotsikoiden jäsentämisen jälkeen.
vaalipiirin jäsennys
Kokoomapohjaisia kieliopillisia käytetään lauseen rakenneosien analysointiin ja määrittämiseen. Kieliopilla voidaan mallintaa tai esittää lauseiden sisäistä rakennetta niiden rakenneosien hierarkkisesti järjestetyn rakenteen avulla. Jokainen sana kuuluu jutussa yleensä tiettyyn sanaluokkaan ja muodostaa eri lausekkeiden pääsanan. Nämä lauseet muodostetaan lauserakennesäännöiksi kutsuttujen sääntöjen perusteella.
Lauserakennesäännöt muodostavat vaalipiirien kieliopin ytimen, koska niissä puhutaan lauseiden eri rakenneosien hierarkiaa ja järjestystä säätelevistä syntakseista ja säännöistä. Nämä säännöt koskevat pääasiassa kahta asiaa.
- ne määrittävät, mitä sanoja käytetään lausekkeiden tai rakenneosien muodostamiseen.
- ne ratkaisevat, miten nämä rakenneosat pitää järjestää yhteen.
lauserakennesäännön yleinen esitys on S → AB , joka kuvaa , että rakenne S koostuu osatekijöistä A ja B, ja järjestys on a, jota seuraa B . Vaikka sääntöjä on useita (katso Luku 1, sivu 19: Text Analytics with Python, Jos haluat sukeltaa syvemmälle), tärkein sääntö kuvaa lauseen tai lausekkeen jakamista. Lauserakennesääntö merkitsee lauseelle tai lauseelle binäärijakoa muodossa S → NP VP, jossa S on lause tai lauseke, ja se jaetaan subjektiin, jota merkitään substantiivilausekkeella (NP) ja predikaattiin, jota merkitään verbilausekkeella (VP).
vaalipiirin jäsennin voidaan rakentaa tällaisten kieliopillisten / sääntöjen pohjalta, jotka ovat yleensä kollektiivisesti saatavilla kontekstivapaana kielioppina (CFG) tai lauserakenteisena kielioppina. Jäsennin käsittelee syöttölauseita näiden sääntöjen mukaisesti ja auttaa jäsentämään puuta.
esimerkki vaalipiirin jäsennyksestä, joka osoittaa sisäkkäisen hierarkkisen rakenteen
käytämme nltk ja StanfordParser tähän jäsentämään puita.
ennakkotiedot: Lataa tästä virallinen Stanfordin jäsennin, joka näyttää toimivan varsin hyvin. Voit kokeilla myöhempää versiota menemällä tälle verkkosivustolle ja tarkistamalla julkaisuhistoria-osion. Kun olet ladannut, pura se tiedostojärjestelmän tunnettuun sijaintiin. Kun se on tehty, olet nyt valmis käyttämään jäsennintä
nltk, johon tutustumme pian.
Stanfordin jäsennin käyttää yleensä PCFG-jäsennintä (probabilistic context-free grammar). PCFG on kontekstiton kielioppi, joka liittää todennäköisyyden jokaiseen tuotantosääntöönsä. Pcfg: stä tuotetun jäsenpuun todennäköisyys on yksinkertaisesti sen tuottamiseen käytettyjen tuotantojen yksittäisten todennäköisyyksien tuottaminen.
(ROOT (SINV (S (NP (NNP US)) (VP (VBZ unveils) (NP (NP (NN world) (POS 's)) (ADJP (RBS most) (JJ powerful)) (NN supercomputer)))) (, ,) (VP (VBZ beats)) (NP (NNP China))))
vaalipiirin jäsenpuu näkyy uutisotsikossamme. Visualisoidaan se ymmärtämään rakennetta paremmin.
from IPython.display import displaydisplay(result)
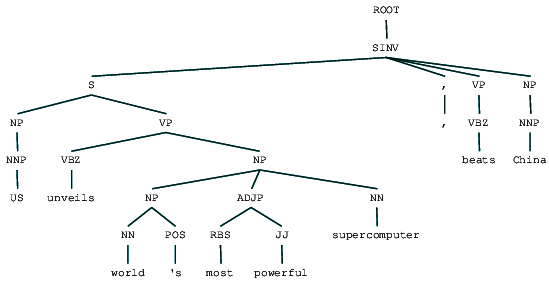
vaalipiirin jäsennelty uutisotsikko
voimme nähdä rakenneosien sisäkkäisen hierarkkisen rakenteen edeltävässä tuotoksessa verrattuna matalassa jäsennyksessä olevaan litteään rakenteeseen. Jos mietit, mitä SINV tarkoittaa, se edustaa käänteistä deklaratiivista lausetta, eli sellaista, jossa subjekti seuraa tensed-verbiä tai modaalia. Katso Penn Treebank viittaus tarpeen etsiä muita tageja.
riippuvuussuhteiden jäsentämisessä
riippuvuussuhteiden jäsentämisessä pyrimme käyttämään riippuvuussuhteisiin perustuvia kieliopillisia sanoja analysoimaan ja päättelemään sekä rakennetta että semanttisia riippuvuuksia ja tokettien välisiä suhteita lauseessa. Riippuvuuden kieliopin perusperiaate on, että missä tahansa kielen lauseessa Kaikilla sanoilla yhtä lukuun ottamatta on jokin suhde tai riippuvuus lauseen muihin sanoihin. Sanaa, jolla ei ole riippuvuutta, kutsutaan lauseen juureksi. Verbi otetaan useimmissa tapauksissa lauseen juureksi. Kaikki muut sanat liittyvät suoraan tai välillisesti juuri-verbiin käyttäen linkkejä, jotka ovat riippuvuuksia.
ottaen huomioon lauseemme ”ruskea kettu on nopea ja hän hyppii laiskan koiran yli”, jos haluaisimme piirtää tälle riippuvuuden syntaksipuun, meillä olisi rakenne
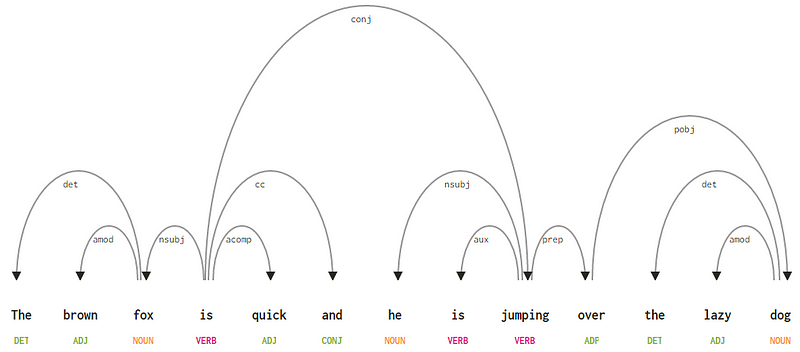
riippuvuusparsipuu lauseelle
näillä riippuvuussuhteilla on kullakin oma merkityksensä, ja ne ovat osa luetteloa universaaleista riippuvuustyypeistä. Tätä käsitellään alkuperäisessä julkaisussa Universal Stanford Dependencies: a Cross-Linguistic Typology, de Marneffe et al, 2014). Voit katsoa tyhjentävän luettelon riippuvuustyypeistä ja niiden merkityksistä täältä.
jos havaitsemme joitakin näistä riippuvuuksista, niitä ei ole liian vaikea ymmärtää.
- riippuvuustunnus det on melko intuitiivinen — se ilmaisee nimellisen pään ja determinaattorin välisen determiner-suhteen. Yleensä POS tag DET-sanalla on myös det-riippuvuussuhde. Esimerkkejä ovat
fox → thejadog → the. - riippuvuustunnus amod tulee sanoista adjektiivi ja tarkoittaa mitä tahansa adjektiivia, joka muuttaa substantiivin merkitystä. Esimerkkejä ovat
fox → brownjadog → lazy. - riippuvuustunniste nsubj tarkoittaa oliota, joka toimii subjektina tai asiamiehenä lausekkeessa. Esimerkkejä ovat
is → foxjajumping → he. - riippuvuudet cc ja conj liittyvät enemmän sanoihin, jotka liittyvät koordinoiviin konjunktioihin . Esimerkkejä ovat
is → andjais → jumping. - riippuvuustunnus aux ilmaisee lausekkeessa olevaa apuverbiä tai toissijaista verbiä. Esimerkki:
jumping → is. - riippuvuustunnus acomp tarkoittaa adjektiivin komplementtia ja toimii lauseen verbin komplementtina tai objektina. Esimerkki:
is → quick - riippuvuustunnisteen prepositio tarkoittaa prepositionaalista modifioijaa, joka yleensä muuttaa substantiivin, verbin, adjektiivin tai preposition merkitystä. Yleensä tätä edustusta käytetään prepositioille, joilla on substantiivi tai substantiivilausekkeen täydennys. Esimerkki:
jumping → over. - riippuvuustunnistetta pobj käytetään merkitsemään preposition objektia . Tämä on yleensä lauseen prepositiota seuraavan substantiivilausekkeen Pää. Esimerkki:
over → dog.
Spacylla oli kahdentyyppisiä englanninkielisiä riippuvuussarjoja sen mukaan, mitä kielimalleja käytät, löydät tarkemmat tiedot täältä. Kielimalleihin perustuen voit käyttää Universal Dependencies Schemeä tai CLEAR Style Dependency Schemeä, joka on saatavilla myös nlp4j: ssä. Nyt leverage spacy ja tulostaa riippuvuudet kunkin token meidän uutiset otsikko.
<---US--->--------<---unveils--->--------<---world--->--------<---'s--->--------<---most--->--------<---powerful--->--------<---supercomputer--->--------<---,--->--------<---beats--->--------<---China--->--------
on ilmeistä, että verbi sykkii juuri, koska sillä ei ole muita riippuvuuksia muihin tokeneihin verrattuna. Jos haluat tietää enemmän jokaisesta merkinnästä, voit aina viitata selkeään riippuvuusjärjestelmään. Voimme myös visualisoida yllä olevat riippuvuudet paremmalla tavalla.
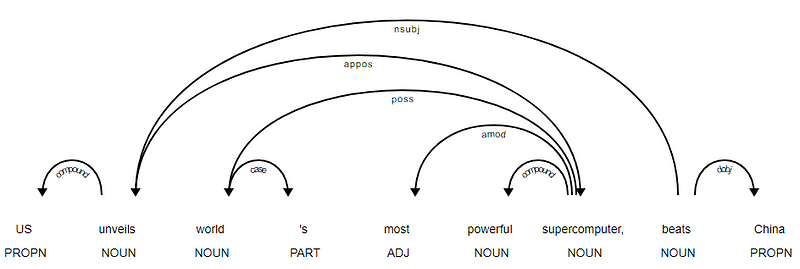
News Headline dependence tree from SpaCy
voit myös hyödyntää nltk ja StanfordDependencyParser visualisoimaan ja rakentamaan riippuvuuspuuta. Esittelemme riippuvuuspuun sekä raa ’ assa että merkityssä muodossa seuraavasti.
(beats (unveils US (supercomputer (world 's) (powerful most))) China)
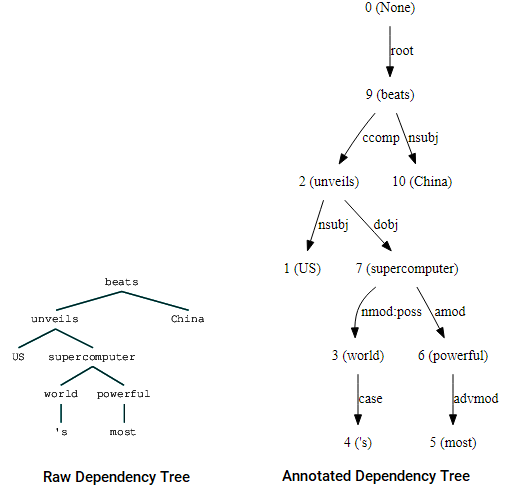
Riippuvuuspuun visualisointi käyttäen nltk: n Stanford-riippuvuutta jäsennin
voit huomata yhtäläisyydet aiemmin hankkimamme puun kanssa. Merkinnät auttavat ymmärtämään, millainen riippuvuus eri polettien välillä on.
Bio: Dipanjan Sarkar on Datatieteilijä @Intel, kirjailija, mentori @ponnahduslauta, kirjailija sekä urheilu-ja komediaaddikti.
Alkuperäinen. Lähetetään uudelleen luvalla.
liittyvät:
- vankat Word2Vec-mallit, joissa on Gensim & Word2Vec — ominaisuuksien soveltaminen koneoppimiseen
- ihmisen tulkittava Koneoppiminen (Osa 1)-Mallitulkinnan tarve ja merkitys
- Syväoppimismenetelmien ja tekstitietojen Ominaisuustekniikan toteuttaminen: Skip-gram-malli