mitä jokaisen ohjelmoijan ehdottomasti, positiivisesti tulee tietää koodauksista ja merkistöistä toimiakseen tekstin kanssa
Jos olet tekemisissä tekstin kanssa tietokoneella, sinun täytyy tietää koodauksista. Aika. Kyllä, vaikka lähetät vain sähköposteja. Vaikka saat vain sähköposteja. Sinun ei tarvitse ymmärtää jokaista yksityiskohtaa, mutta sinun täytyy ainakin tietää, mistä tässä koodausjutussa on kyse. Ja hyvät uutiset ensin: vaikka aiheesta voi tulla sotkuinen ja sekava, perusidea on todella, todella yksinkertainen.
Tämä artikkeli käsittelee koodauksia ja merkistöjä. Artikkeli Joel Spolsky oikeus ehdoton minimi jokainen ohjelmistokehittäjä ehdottomasti, positiivisesti täytyy tietää Unicode ja merkistöjä (Ei tekosyitä!) on mukava johdatus aiheeseen ja nautin suuresti sen lukemisesta silloin tällöin. Epäröin viitata ihmisiä, joilla on vaikeuksia ymmärtää koodaus ongelmia, vaikka koska, vaikka viihdyttävä, se on melko kevyt todellinen teknisiä yksityiskohtia. Toivon, että tämä artikkeli voi valaista hieman, mitä tarkalleen koodaus on ja miksi kaikki teksti mokaa, kun vähiten sitä tarvitaan. Tämä artikkeli on suunnattu kehittäjille (keskittyen PHP: hen), mutta tietokoneen käyttäjän tulisi voida hyötyä siitä.
perusasioiden selvittäminen
kaikki ovat tästä jollain tasolla tietoisia, mutta jotenkin tämä tieto tuntuu yhtäkkiä katoavan tekstikeskustelussa, joten otetaan se ensin esiin: tietokone ei voi tallentaa ”kirjaimia”, ”numeroita”, ”kuvia” tai mitään muutakaan. Se voi tallentaa ja työskennellä vain bittien kanssa. Bitillä voi olla vain kaksi arvoa: yes tai notrue tai false1 tai 0 tai mitä muuta haluat kutsua näitä kahta arvoa. Koska tietokone toimii sähkön kanssa, ”todellinen” bitti on sähköhiukkanen, jota joko on tai ei ole. Ihmisille tämä esitetään yleensä käyttämällä 1 ja 0 ja pysyn tässä konventiossa koko tämän artikkelin ajan.
käyttääksemme bittejä edustamaan mitään muuta kuin bittejä, tarvitsemme sääntöjä. Meidän täytyy muuntaa sekvenssi bittejä jotain kirjaimia, numeroita ja kuvia käyttäen koodaus scheme, tai koodaus lyhyesti. Näin:
01100010 01101001 01110100 01110011b i t stässä koodauksessa 01100010 tarkoittaa b-kirjainta, 01101001 I-kirjainta, 01110100 tarkoittaa ”t” ja 01110011 ”s”. Tietty bittisarja tarkoittaa kirjainta ja kirjain tiettyä bittisarjaa. Jos pystyt pitämään tämän päässäsi 26 kirjaimen ajan tai olet todella nopea etsimään tavaroita pöydästä, voisit lukea bittejä kuin kirjaa.
yllä oleva koodausjärjestelmä sattuu olemaan ASCII. Jono 1s ja 0s jaetaan kahdeksanbittisiin osiin kutakin (lyhyesti tavu). ASCII-koodaus määrittää taulukon, joka kääntää tavuja ihmisen luettaviksi kirjaimiksi. Tässä on lyhyt ote tuosta taulukosta:
| bits | character |
|---|---|
01000001 |
A |
01000010 |
B |
01000011 |
C |
01000100 |
D |
01000101 |
E |
01000110 |
F |
There are 95 human readable ASCII-taulukossa määritellyt merkit, mukaan lukien kirjaimet A-Z sekä ylä-että pienaakkosilla, numerot 0-9, kourallinen välimerkkejä ja merkkejä, kuten dollarin symboli, ampersand ja muutama muu. Se sisältää myös 33 arvoja asioita, kuten tilaa, viivasyöttö, välilehti, backspace ja niin edelleen. Nämä eivät ole tulostettavia sinänsä, mutta silti nähtävissä jossain muodossa ja hyödyllisiä ihmisille suoraan. Useat arvot ovat hyödyllisiä vain tietokoneelle, kuten koodit, joilla merkitään tekstin alkua tai loppua. Yhteensä ASCII-merkistössä on määritelty 128 merkkiä, mikä on mukava pyöreä luku (tietokoneita käsitteleville ihmisille), sillä se käyttää kaikkia mahdollisia 7 bitin yhdistelmiä (000000000000010000010 kautta 1111111).1
ja siinä se, tapa esittää ihmisen luettavaa tekstiä vain 1s ja 0s.
01001000 01100101 01101100 01101100 01101111 00100000 01010111 01101111 01110010 01101100 01100100”Hello World”
tärkeät termit
Jos haluat koodata jotain ASCII-kielellä, seuraa taulukkoa oikealta vasemmalle korvaten kirjaimet bitteihin. Jos haluat purkaa bittijonon ihmisen luettaviksi merkeiksi, seuraa taulukkoa vasemmalta oikealle ja korvaa bitit kirjaimilla.
koodaa|enˈkōd/
verbi
Muunna koodattuun muotoonkoodi|kōd /
substantiivi
järjestelmä, jossa sanat, kirjaimet, luvut tai muut symbolit korvataan muilla sanoilla, kirjaimilla jne.
koodaus tarkoittaa jonkin käyttämistä edustamaan jotain muuta. Koodaus on joukko sääntöjä, joilla voidaan muuntaa jotain yhdestä edustuksesta toiseen.
muita termejä, jotka ansaitsevat tässä yhteydessä selvennyksen:
merkistö, merkistö, merkistö, joka voidaan koodata. ”ASCII-koodaus käsittää 128 merkin merkistön.”Lähinnä synonyymi ”koodaukselle”. koodisivu a” sivu ” koodeja, jotka kartoittavat merkin numero-tai bittisarjaan. ”The table”. Pohjimmiltaan synonyymi ”koodaus”. string a string on joukko kohteita koukussa yhdessä. Bittijono on joukko bittejä, kuten01010011. Merkistö on joukko merkkejä,like this. Synonyymi ”sekvenssi”.
binäärinen, oktaalinen, desimaalinen, hex
on monia tapoja kirjoittaa numeroita. 10011111 binäärissä on 237 oktaalissa on 159 desimaalissa on 9F heksadesimaalissa. Ne kaikki edustavat samaa arvoa, mutta heksadesimaali on lyhyempi ja helppolukuisempi kuin binääri. Aion pysyä binary koko tämän artikkelin saada kohta poikki paremmin ja säästää lukija yhden kerroksen abstraktio. Älä hätäänny nähdä merkkikoodeja, joihin viitataan muissa huomautuksissa muualla, se on kaikki sama asia.
Excusez-moi?
nyt kun tiedämme mistä puhumme, sanotaan näin: 95 merkkiä ei todellakaan ole paljon, kun puhutaan kielistä. Se kattaa englannin kielen perusteet, mutta entä risqué-kirjeen kirjoittaminen ranskaksi? Straßenübergangsänderungsgesetz saksaksi? Kutsu smörgåsbordiin ruotsiksi? Ei ASCII: ssa. ASCII: ssa ei ole määritelty, miten jokin kirjain é, ß, ü, ä, ö tai å tulisi esittää, joten niitä ei voi käyttää.
”mutta katsokaa”, eurooppalaiset sanoivat, ”yhteisessä tietokoneessa, jonka tavu on 8 bittiä, ASCII tuhlaa kokonaisen bitin, joka asetetaan aina 0! Voimme käyttää sitä vähän puristaa koko ” toinen 128 arvot tuohon taulukkoon!”Ja niin he tekivät. Siitä huolimatta vokaalin silottamiseen, viipaloimiseen, viiltämiseen ja pistämiseen on yli 128 tapaa. Kaikkia kaikissa eurooppalaisissa kielissä käytettyjä kirjainten ja kiemuroiden variaatioita ei voida esittää samassa taulukossa enintään 256 arvolla. Joten mitä maailma päätyi on runsaasti koodaus järjestelmiä, standardeja, de-facto standardeja ja puolistandardeja, jotka kaikki kattavat eri osajoukko merkkejä. Jonkun piti kirjoittaa dokumentti Ruotsista tshekiksi, huomasi, että mikään koodaus ei kattanut molempia kieliä ja keksi yhden. Tai niin se varmaan meni lukemattomia kertoja.
eikä pidä unohtaa Venäjää, hindiä, arabiaa, hepreaa, Koreaa ja kaikkia muita tällä planeetalla tällä hetkellä käytössä olevia kieliä. Puhumattakaan niistä, jotka eivät ole enää käytössä. Kun olet ratkaissut ongelman, miten kirjoittaa sekakielisiä asiakirjoja kaikilla näillä kielillä, kokeile itseäsi kiinaksi. Tai Japanilainen. Molemmissa on kymmeniä tuhansia merkkejä. Sinulla on 256 mahdollista arvoa tavulle, joka koostuu 8-bittisestä. Mene!
monitavuiset koodaukset
sellaisen taulukon luomiseksi, joka kartoittaa merkit kirjaimiksi yli 256 merkkiä käyttävälle kielelle, yksi tavu ei yksinkertaisesti riitä. Käyttämällä kahta tavua (16 bittiä), on mahdollista koodata 65,536 erillistä arvoa. BIG-5 on sellainen kaksitavuinen koodaus. Sen sijaan, että se rikkoisi merkkijonon bittejä lohkoiksi kahdeksan, se hajottaa sen lohkoiksi 16 ja siinä on iso (tarkoitan, ISO) taulukko, joka määrittää, mille merkille kukin bittiyhdistelmä kartoittaa. BIG-5 perusmuodossaan kattaa enimmäkseen perinteisiä kiinalaisia merkkejä. GB18030 on toinen koodaus, joka periaatteessa tekee saman asian, mutta sisältää sekä perinteisiä että yksinkertaistettuja kiinalaisia merkkejä. Ja ennen kuin kysyt, kyllä, on koodauksia, jotka kattavat vain yksinkertaistettua Kiinaa. Ei voi olla vain yksi koodaus nyt, eihän?
tässä pieni ote GB18030-taulukosta:
| bits | character |
|---|---|
10000001 01000000 |
丂 |
10000001 01000001 |
丄 |
10000001 01000010 |
丅 |
10000001 01000011 |
丆 |
10000001 01000100 |
丏 |
GB18030 covers quite a range of characters (including a large part of latin merkit), mutta lopulta on vielä yksi erikoistunut koodausformaatti monien joukossa.
Unicode sekasortoon

lopulta joku sai sotkusta tarpeekseen ja lähti takomaan rengasta sitomaan ne kaikki yhteen koodaukseen standardi kaikkien koodausstandardien yhtenäistämiseksi. Tämä standardi on Unicode. Se määrittelee periaatteessa valtavan taulukon 1,114,112 koodipistettä, joita voidaan käyttää kaikenlaisille kirjaimille ja symboleille. Siinä on paljon koodattavaa kaikille eurooppalaisille, Lähi-idän, Kaukoidän, etelän, pohjoisen, lännen, esihistorioitsijoille ja tulevaisuuden hahmoille, joista ihmiskunta tietää.2 käyttämällä Unicode, voit kirjoittaa asiakirjan, joka sisältää lähes mitä tahansa kieltä käyttäen mitä tahansa merkkiä voit kirjoittaa tietokoneeseen. Tämä oli joko mahdotonta tai erittäin vaikea saada juuri ennen Unicode tuli. Unicodessa on jopa epävirallinen osio Klingonille. Unicode onkin sen verran iso, että se mahdollistaa epäviralliset, yksityiskäytössä olevat alueet.
joten, kuinka monta bittiä Unicode käyttää koodaamaan kaikkia näitä merkkejä? Kukaan. Koska Unicode ei ole koodaus.
sekaisin? Monet näyttävät olevan. Unicode määrittelee ennen kaikkea taulukon koodipisteistä merkeille. Se on hieno tapa sanoa ” 65 tarkoittaa A: ta, 66 tarkoittaa B: tä ja 9731 tarkoittaa ☃” (vakavasti puhuen). Se, miten nämä Koodipisteet oikeasti koodataan biteiksi, on eri asia. Kaksi tavua ei riitä edustamaan 1 114 112: ta eri arvoa. Kolme tavua on, mutta kolme tavua on usein hankala työstettävä, joten neljä tavua olisi mukava minimi. Mutta, ellet todella käyttää kiinalaista tai joitakin muita merkkejä suuria numeroita, jotka vievät paljon bittiä koodata, et koskaan aio käyttää valtava kimpale näistä neljästä tavusta. Jos kirjain ”A”olisi aina koodattu 00000000 00000000 00000000 01000001,” B”aina 00000000 00000000 00000000 01000010 ja niin edelleen, mikä tahansa asiakirja paisuisi nelinkertaiseksi tarvittavaan kokoon.
tämän optimoimiseksi on olemassa useita tapoja koodata Unicode-koodipisteitä biteiksi. UTF-32 on sellainen koodaus, joka koodaa kaikki Unicode-Koodipisteet käyttäen 32 bittiä. Eli neljä tavua per merkki. Se on hyvin yksinkertainen, mutta usein tuhlaa paljon tilaa. UTF-16 ja UTF-8 ovat vaihtuvapituisia koodauksia. Jos merkki voidaan esittää yhdellä tavulla (koska sen koodipiste on hyvin pieni luku), UTF-8 koodaa sen yhdellä tavulla. Jos se vaatii kaksi tavua, se käyttää kahta tavua ja niin edelleen. Siinä on monimutkaisia tapoja käyttää tavun korkeimpia bittejä merkkinä siitä, kuinka monta tavua merkki koostuu. Tämä voi säästää tilaa, mutta voi myös tuhlata tilaa, jos näitä signaalibittejä on käytettävä usein. UTF-16 on keskellä käyttäen vähintään kahta tavua ja kasvaa tarvittaessa jopa neljään tavuun.
| character | encoding | bits |
|---|---|---|
| A | UTF-8 | 01000001 |
| A | UTF-16 | 00000000 01000001 |
| A | UTF-32 | 00000000 00000000 00000000 01000001 |
| あ | UTF-8 | 11100011 10000001 10000010 |
| あ | UTF-16 | 00110000 01000010 |
| あ | UTF-32 | 00000000 00000000 00110000 01000010 |
ja siinä kaikki. Unicode on suuri taulukkomerkki numeroille ja eri UTF-koodaukset määrittelevät, miten nämä numerot koodataan bitteinä. Kaiken kaikkiaan Unicode on jälleen yksi koodausjärjestelmä. Siinä ei ole mitään erikoista, se vain yrittää peittää kaiken samalla kun on tehokas. Ja se on hyvä asia.™
Koodipisteet
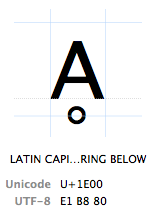
merkkeihin viitataan niiden ”Unicode-koodipisteellä”. Unicode – Koodipisteet kirjoitetaan heksadesimaaleina (jotta numerot pysyisivät lyhyempinä), joita edeltää ”U+” (sitä ne vain tekevät, sillä ei ole muuta merkitystä kuin ”tämä on Unicode-koodipiste”). Merkillä Ḁ on Unicode – koodipiste U + 1E00. Muissa (desimaalisanoissa) se on Unicode-taulukon 7680.merkki. Sen virallinen nimi on”Latinalainen Iso A-kirjain, jonka alla on rengas”.
TL;dr
yhteenveto kaikesta edellä mainitusta: mikä tahansa merkki voidaan koodata moneen eri bittisekvenssiin ja mikä tahansa tietty bittisekvenssi voi edustaa monia eri merkkejä riippuen siitä, mitä koodausta käytetään niiden lukemiseen tai kirjoittamiseen. Syynä on yksinkertaisesti se, että eri koodaukset käyttävät eri bittimääriä merkkiä kohden ja eri arvoja edustamaan eri merkkejä.
| bits | encoding | characters |
|---|---|---|
11000100 01000010 |
Windows Latin 1 | ÄB |
11000100 01000010 |
Mac Roman | ƒB |
11000100 01000010 |
GB18030 | 腂 |
| characters | encoding | bits |
|---|---|---|
| Føö | Windows Latin 1 | 01000110 11111000 11110110 |
| Føö | 01000110 10111111 10011010 |
|
| føö | UTF-8 | 01000110 11000011 10111000 11000011 10110110 |
harhaluuloja, sekaannuksia ja ongelmia
sanottuamme kaiken tämän, tulemme monien käyttäjien ja ohjelmoijien päivittäin kokemiin todellisiin ongelmiin, miten nämä ongelmat liittyvät kaikkeen edellä mainittuun ja mikä niiden ratkaisu on. Suurin ongelma on:
miksi ihmeessä hahmoni ovat sekaisin?!
ÉGÉìÉRÅ;Jos tämä $string olisi yksitavuisessa koodauksessa, tämä antaisi ensimmäisen merkin. Mutta vain siksi, että” merkki ”yhtyy” tavun ” kanssa yhden tavun koodauksessa. PHP yksinkertaisesti antaa meille ensimmäisen tavun ajattelematta ”merkkejä”. Merkkijonot ovat tavusarjoja PHP: lle, ei enempää eikä vähempää. Kaikki tämä ”luettava hahmo” – juttu on inhimillistä, eikä PHP välitä siitä.
01000100 01101111 01101110 00100111 01110100D o n ' t01100011 01100001 01110010 01100101 00100001c a r e !sama koskee monia vakiofunktioita, kuten substrstrpostrim ja niin edelleen. Ei-tuki syntyy, jos tavun ja merkin pituuden välillä on ristiriita.
11100110 10111100 10100010 11100101 10101101 10010111漢 字
käyttämällä $string yllä olevalla merkkijonolla saadaan jälleen ensimmäinen tavu, joka on 11100110. Toisin sanoen kolmannes kolmen tavun merkistä”漢”. 11100110 on itsessään virheellinen UTF-8-sekvenssi, joten merkkijono on nyt poikki. Jos siltä tuntui, voisi yrittää tulkita, että jossain muussa koodauksessa, jossa 11100110 edustaa kelvollista merkkiä, jolloin tuloksena on jokin satunnainen merkki. Pidä hauskaa, mutta älä käytä sitä tuotannossa.
ja siinä kaikki. ”PHP ei natiivisti tue Unicodea” tarkoittaa yksinkertaisesti sitä, että useimmat PHP-funktiot olettavat yhden tavun = yhden merkin, mikä voi johtaa siihen, että se pilkkoo monitavuisia merkkejä kahtia tai laskee merkkijonojen pituuden väärin, jos käytät naiivisti ei-monitavuisia funktioita monitavuisilla merkkijonoilla. Se ei tarkoita, etteikö PHP: ssä voisi käyttää Unicodea tai että jokainen Unicode-merkkijono tarvitsee siunauksen utf8_encode tai muuta vastaavaa hölynpölyä.
onneksi on olemassa Multibyte String extension, joka toistaa kaikki tärkeät merkkijonofunktiot monitavuisella tavalla. Käyttämällä mb_substr($string, 0, 1, 'UTF-8') yllä olevalla merkkijonolla oikein palauttaa 11100110 10111100 10100010, joka on koko ”漢” – merkki. Koska mb_ funktiot joutuvat nyt oikeasti miettimään, mitä ne tekevät, niiden täytyy tietää, mitä koodausta ne työstävät. Siksi jokainen mb_ funktio hyväksyy myös $encoding parametrin. Vaihtoehtoisesti tämä voidaan asettaa globaalisti kaikille mb_ funktioille käyttäen mb_internal_encoding.
käyttämällä ja väärinkäyttämällä PHP: n koodausten käsittelyä
koko ongelma PHP: n (ei-)tuesta Unicodelle on, että se ei vain välitä. Merkkijonot ovat tavusarjoja PHP: lle. Erityisesti tavuilla ei ole väliä. PHP ei tee merkkijonoilla mitään muuta kuin pitää ne tallennettuna muistiin. PHP yksinkertaisesti ei ole mitään käsitettä joko merkkejä tai koodauksia. Ja ellei se yritä manipuloida merkkijonoja, sen ei myöskään tarvitse; se vain pitää kiinni tavuista, jotka joku muu saattaa lopulta tulkita merkkeiksi. PHP: n ainoa vaatimus koodauksille on, että PHP: n lähdekoodi on tallennettava ASCII-yhteensopivaan koodaukseen. PHP jäsennin etsii tiettyjä merkkejä, jotka kertovat, mitä tehdä. $00100100) lähettää muuttujan alun, =00111101) tehtävän, "00100010) merkkijonon alku ja loppu ja niin edelleen. Kaikki muu, jolla ei ole mitään erityistä merkitystä jäsentäjälle, otetaan vain kirjaimellisena tavusarjana. Se sisältää kaiken välillä lainauksia, kuten edellä. Tämä tarkoittaa seuraavaa:
-
PHP-lähdekoodia ei voi tallentaa ASCII-yhteensopimattomaan koodaukseen. Esimerkiksi UTF-16: ssa a
"on koodattu00000000 00100010. PHP: lle, joka yrittää lukea kaiken ASCII: ksi, se onNULtavu, jota seuraa".PHP saa todennäköisesti Hikan, jos joka toinen sen löytämä merkki onNULtavu. -
voit tallentaa PHP-lähdekoodin mihin tahansa ASCII-yhteensopivaan koodaukseen. Jos ensimmäiset 128 koodipistettä koodaus areidentical ASCII, PHP voi jäsentää sen. Kaikki merkit, jotka ovat jollakin tavalla merkittäviä PHP: lle, ovat ASCII: n määrittelemien 128 koodipisteen sisällä. Jos string literals sisältää mitään koodia pistettä pidemmälle, PHP ei välitä. Voit tallentaa PHP sourcecode ISO-8859-1, Mac Roman, UTF-8 tai muu ASCII-yhteensopiva koodaus. String literals skriptisi willhave mitä koodaus olet tallentanut lähdekoodin.
-
mikä tahansa PHP: llä käsittelemäsi ulkoinen tiedosto voi olla missä tahansa koodauksessa. If PHP doesn ’ t need to jäsentää it, thereare no requirements to meet to keep the PHP jäsennin happy.
$foo = file_get_contents('bar.txt');edellä oleva yksinkertaisesti lukee bitit
bar.txtmuuttujaksi$foo. PHP ei yritä tulkita, muuntaa, koodata tai muuten näprätä sisältöä. Tiedosto voi sisältää jopa binääridataa,kuten kuvan, PHP ei välitä. -
Jos sisäisten ja ulkoisten koodausten on täsmättävä, niiden on täsmättävä. Yleinen tapaus on lokalisointi, jossa lähdekoodi sisältää jotain
echo localize('Foobar')ja ulkoinen lokalisointitiedosto sisältää jotain tämän suuntaista:msgid "Foobar"msgstr "フーバー"molemmilla ”Foobar” – merkkijonoilla on oltava identtinen bittiesitys, jos haluat löytää oikean lokalisoinnin.Jos lähdekoodi olisi tallennettu ASCII: een mutta lokalisointitiedosto UTF-16: een, merkkijonot eivät täsmäisi.Joko jonkinlainen koodausmuunnos olisi tarpeen tai koodaustietoisen merkkijonosovitustoiminnon käyttö.
tarkkanäköinen lukija saattaa tässä vaiheessa kysyä, onko mahdollista tallentaa vaikkapa UTF-16 tavujärjestys ASCII-koodatun lähdekooditiedoston merkkijonon sisälle, johon vastaus olisi: ehdottomasti.
echo "UTF-16";Jos voit tuoda tekstieditorisi tallentamaan echo " ja "; osia ASCII: ssa ja vain UTF-16 UTF-16: ssa, tämä toimii mainiosti. Tarvittava binääriesitys, joka näyttää tältä:
01100101 01100011 01101000 01101111 00100000 00100010e c h o "11111110 11111111 00000000 01010101 00000000 01010100(UTF-16 marker) U T00000000 01000110 00000000 00101101 00000000 00110001F - 100000000 00110110 00100010 001110116 " ;ensimmäinen rivi ja kaksi viimeistä tavua ovat ASCII. Loppuosa on UTF-16, jossa on kaksi tavua per merkki. Johtava 11111110 11111111 rivillä 2 on tussi, joka vaaditaan UTF-16-koodatun tekstin alkuun (vaatii UTF-16-standardi, PHP ei välitä pätkääkään). Tämä PHP script onneksi tulostetaan merkkijono” UTF-16 ”koodattu UTF-16, koska se yksinkertainen lähdöt tavuja välillä kaksi lainausmerkit, joka sattuu edustamaan tekstiä” UTF-16 ” koodattu UTF-16. Lähdekooditiedosto ei kuitenkaan ole täysin kelvollinen ASCII eikä UTF-16, joten työskentely sen kanssa tekstieditorissa ei ole hauskaa.
Alarivi
PHP tukee Unicodea, tai oikeastaan mitä tahansa koodausta, ihan hyvin, kunhan tietyt vaatimukset täyttyvät jäsentäjän pitämiseksi tyytyväisenä ja ohjelmoija tietää mitä tekee. Sinun tarvitsee vain olla varovainen manipuloimalla merkkijonoja, joka sisältää viipalointi, leikkaus, laskenta ja muut toiminnot, jotka on tapahduttava merkki tasolla sijaan tavu tasolla. Jos et ”tee mitään” kanssa Jouset lisäksi käsittelyssä ja outputting niitä, sinulla tuskin on mitään ongelmia PHP: n tukea koodauksia, että sinulla ei olisi millään muulla kielellä samoin.
Encoding-aware languages
Mitä Unicodea tukeva kieli sitten tarkoittaa? Javascript tukee esimerkiksi Unicodea. Itse asiassa, mikä tahansa merkkijono Javascript on UTF-16 koodattu. Itse asiassa, se on ainoa asia, Javascript käsittelee. Javascriptissä ei voi olla merkkijonoa, joka ei ole UTF-16-koodattu. Javascript palvoo Unicodea siinä määrin, että ydinkielellä ei ole mahdollisuutta käsitellä mitään muuta koodausta. Koska Javascript on useimmiten käynnissä selaimessa, se ei ole ongelma, koska selain voi hoitaa arkisen logistiikan koodaus ja dekoodaus Tulo ja Lähtö.
Muut kielet ovat yksinkertaisesti koodaustietoisia. Sisäisesti ne tallentavat merkkijonoja tiettyyn koodaukseen, usein UTF-16: een. Heille on puolestaan kerrottava tai yritettävä havaita kaiken tekstiin liittyvän koodaus. Heidän täytyy tietää, mitä koodaus lähdekoodi on tallennettu, mitä koodaus tiedoston he pitäisi lukea on, mitä koodaus haluat tulostaa tekstiä; ja he muuntaa koodaukset lennossa tarpeen jonkin ilmentymä Unicode välikätenä. They ’ re doing the same thing you can/should / need to do in PHP semi-automatically behind the scenes. Se ei ole parempi eikä huonompi kuin PHP, vain erilainen. Mukavaa siinä on se, että tavalliset kielitoiminnot, jotka käsittelevät merkkijonoja, toimivat vain™, kun taas PHP: ssä on varattava jonkin verran huomiota siihen, sisältääkö merkkijono monitavuisia merkkejä vai ei, ja valittava merkkijonon manipulointitoiminnot sen mukaisesti.
Unicoden syvyydet
koska Unicode käsittelee monia erilaisia skriptejä ja monia erilaisia ongelmia, siinä on paljon syvyyttä. Esimerkiksi Unicode-standardi sisältää tietoa esimerkiksi CJK-ideografien yhdistämisen kaltaisista ongelmista. Se tarkoittaa tietoa siitä, että kaksi tai useampia kiinalaisia / japanilaisia / korealaisia merkkejä todella edustavat samaa merkkiä hieman eri kirjoitustavoissa. Tai säännöt pienaakkosesta suuraakkoseksi, päinvastoin ja edestakaiseksi, joka ei ole aina yhtä suoraviivainen kaikissa skripteissä kuin useimmissa länsieurooppalaisissa latinalaisperäisissä skripteissä. Joitakin merkkejä voidaan myös esittää käyttämällä erilaisia koodipisteitä. Esimerkiksi kirjain ”ö”voidaan esittää koodipisteellä U+00f6 (”Latinalainen pieni kirjain O DIAEREESILLÄ”) tai kahdella koodipisteellä U+006f (”Latinalainen pieni kirjain O”) ja U+0308 (”yhdistämällä DIAEREESI”), eli kirjaimella” o ”yhdistettynä””. UTF-8: ssa se on joko kaksitavuinen sekvenssi 11000011 10110110 tai kolmitavuinen sekvenssi 01101111 11001100 10001000, jotka molemmat edustavat samaa ihmisen luettavaa merkkiä. Sellaisenaan Unicode-standardin sisällä on sääntöjä normalisoinnista,eli miten jompikumpi näistä muodoista voidaan muuntaa toisiksi. Tämä ja paljon muuta ei kuulu tämän artiklan soveltamisalaan, mutta siitä on oltava tietoinen.
lopullinen TL;dr
- teksti on aina bittisarja, joka on käännettävä ihmisen luettavaksi tekstiksi hakutaulukoiden avulla. Jos käytetään väärää hakutaulukkoa, käytetään väärää merkkiä.
- et koskaan ole suoraan tekemisissä ”merkkien” tai ”tekstin” kanssa, vaan käsittelet aina bittejä, jotka nähdään useiden abstraktiokerrosten läpi. Virheelliset tulokset ovat merkki siitä, että yksi abstraktio kerrokset epäonnistuvat.
- Jos kaksi systeemiä puhuu keskenään, niiden on aina määriteltävä, millä koodauksella ne haluavat puhua toisilleen. Yksinkertaisin esimerkki tästä on tämä sivusto kertoo selaimesi, että se on koodattu UTF-8.
- tänä päivänä standardikoodaus on UTF-8, koska se voi koodata lähes minkä tahansa kiinnostavan merkin, on taaksepäin yhteensopiva de-facto perustason ASCII: n kanssa ja on kuitenkin suhteellisen tilatehokkas valtaosaan käyttötapauksista.
- muillakin koodauksilla on vielä silloin tällöin käyttötarkoituksensa, mutta sinulla pitäisi olla konkreettinen syy siihen, että haluat käsitellä merkistöihin liittyviä päänsärkyjä, jotka voivat koodata vain Unicode-osajoukon.
- yhden tavun = yhden hahmon päivät ovat ohi, ja sekä ohjelmoijien että ohjelmien on otettava tästä kiinni.
nyt sinulla ei todellakaan pitäisi olla enää mitään tekosyitä, kun seuraavan kerran höpötät jotain tekstiä.
-
kyllä, se tarkoittaa, että ASCII voidaan tallentaa ja siirtää käyttäen vain 7 bittiä ja se usein onkin. Ei, Tämä ei kuulu tämän artikkelin soveltamisalaan ja argumentin vuoksi oletamme, että korkein bitti on ”hukkaan” ASCII: ssa. ↩
-
Ja jos se ei ole, sitä laajennetaan. Se on tapahtunut jo useita kertoja. ↩
-
huomaa, että kun käytän termiä ”alkaa” yhdessä ”tavun” kanssa, tarkoitan sitä ihmisen luettavissa olevasta näkökulmasta. ↩
-
Lue UTF-8-spesifikaatio, jos haluat noudattaa tätä kynällä ja paperilla. ↩
-
Hei, Olen ohjelmoija, En biologi. ↩
-
ja tietenkään ei tule tuoretta taustajoukkoa. ↩
-
”Unicode-merkki” on koodipiste Unicode-taulukossa. ”あ” ei ole Unicode-merkki, vaan hiragana-kirjain あ. Sille on olemassa Unicode-koodipiste, mutta se ei tee itse kirjaimesta Unicode-merkkiä. ”UTF-8-merkki ”on oksymoroni, mutta se voidaan venyttää tarkoittamaan teknisesti niin sanottua” UTF-8-sekvenssiä”, joka on yhden, kahden, kolmen tai neljän tavun tavujono, joka edustaa yhtä Unicode-merkkiä. Molemmat termit käytetään usein merkityksessä ”mikä tahansa kirjain, joka ei ole osa minun näppäimistö” vaikka, mikä tarkoittaa mitään. ↩
http://www.php.net/manual/en/function.utf8-encode.php↩
tekijästä
David C. Zentgraf on osittain Japanissa ja Euroopassa toimiva web-kehittäjä, joka on säännöllinen Stack Overflow-sivustolla.Jos sinulla on palautetta, kritiikkiä tai lisäyksiä,voit vapaasti kokeilla @deceze Twitterissä, ottaa Valistunut arvaus hänen sähköpostiosoitteensa tai etsiä sen käyttämällä aikaa kunnioitettuja menetelmiä.Tämä artikkeli on julkaistu kunststube.net ja ei, ”Kunststubessa”ei ole Rivoa sanaa.