wat elke programmeur absoluut, positief moet weten over coderingen en tekensets om te werken met tekst
als je te maken hebt met tekst in een computer, moet je weten over coderingen. Periode. Ja, zelfs als u alleen e-mails verzendt. Zelfs als u alleen e-mails ontvangt. Je hoeft niet elk detail te begrijpen, maar je moet op zijn minst weten waar dit hele” coderen ” ding over gaat. En eerst het goede nieuws: hoewel het onderwerp rommelig en verwarrend kan worden, is het basisidee echt, echt eenvoudig.
Dit artikel gaat over coderingen en tekensets. Een artikel van Joel Spolsky getiteld Het Absolute Minimum elke software ontwikkelaar absoluut, positief moet weten over Unicode en karakter Sets (geen Excuses!) is een leuke introductie tot het onderwerp en ik geniet er enorm van om het af en toe te lezen. Ik aarzel om mensen te verwijzen naar het die moeite hebben met het begrijpen van codering problemen al omdat, terwijl onderhoudend, het is vrij licht op de werkelijke technische details. Ik hoop dat dit artikel wat meer licht kan werpen op wat precies een codering is en waarom al uw tekst verpest wanneer je het minst nodig hebt. Dit artikel is gericht op ontwikkelaars (met een focus op PHP), maar elke computer gebruiker moet kunnen profiteren van het.
de basis recht zetten
Iedereen is zich hier op een bepaald niveau van bewust, maar op een of andere manier lijkt deze kennis plotseling te verdwijnen in een discussie over tekst, dus laten we het er eerst uit halen: een computer kan “letters”, “cijfers”, “afbeeldingen” of iets anders niet opslaan. Het enige wat het kan opslaan en werken met zijn bits. Een bit kan slechts twee waarden hebben: yes of notrue of false1 of 0 of hoe u deze twee waarden ook wilt noemen. Omdat een computer met elektriciteit werkt, is een “echt” bit een stip van elektriciteit die er wel of niet is. Voor mensen wordt dit meestal weergegeven met 1 en 0 en ik blijf bij deze conventie in dit artikel.
om bits te gebruiken om iets anders dan bits weer te geven, hebben we regels nodig. We moeten een reeks bits omzetten in iets als letters, cijfers en afbeeldingen met behulp van een coderingsschema, of kortweg codering. Als volgt:
01100010 01101001 01110100 01110011b i t sIn deze codering staat 01100010 voor de letter “b”, 01101001 voor de letter “i”, 01110100 voor “t” en 01110011 voor “s”. Een bepaalde opeenvolging van bits staat voor een letter en een letter staat voor een bepaalde opeenvolging van bits. Als je dit 26 letters in je hoofd kunt houden of heel snel dingen in een tafel kunt opzoeken, kun je stukjes lezen als een boek.
het bovenstaande coderingsschema is toevallig ASCII. Een string van 1s en 0s wordt opgesplitst in delen van elk acht bits (een byte). De ASCII-codering specificeert een tabel die bytes vertaalt naar leesbare letters. Hier is een kort fragment van die tabel:
| bits | character |
|---|---|
01000001 |
A |
01000010 |
B |
01000011 |
C |
01000100 |
D |
01000101 |
E |
01000110 |
F |
There are 95 human readable tekens die zijn gespecificeerd in de ASCII-tabel, inclusief de letters A tot en met Z zowel in hoofdletters als kleine letters, de cijfers 0 tot en met 9, een handvol leestekens en tekens zoals het dollarsymbool, de ampersand en een paar anderen. Het bevat ook 33 waarden voor dingen zoals ruimte, lijn feed, tab, backspace en ga zo maar door. Deze zijn niet per se bedrukbaar, maar nog steeds zichtbaar in een of andere vorm en direct bruikbaar voor mensen. Een aantal waarden zijn alleen nuttig voor een computer, zoals codes om het begin of einde van een tekst aan te geven. In totaal zijn er 128 tekens gedefinieerd in de ASCII-codering, wat een mooi rond getal is (voor mensen die met computers te maken hebben), omdat het alle mogelijke combinaties van 7 bits gebruikt (000000000000010000010 via 1111111).1
en daar heb je het, de manier om voor mensen leesbare tekst weer te geven met alleen 1s en 0s.
01001000 01100101 01101100 01101100 01101111 00100000 01010111 01101111 01110010 01101100 01100100“Hello World”
belangrijke termen
om iets in ASCII te coderen, volg de tabel van rechts naar links en vervang bits met letters. Om een reeks bits in leesbare tekens te decoderen, volgt u de tabel van links naar rechts en vervangt u Bits door letters.
coderen / endikōd/
werkwoord
omzetten in een gecodeerde vormcode|kōd /
zelfstandig naamwoord
Een systeem van woorden, letters, cijfers of andere symbolen die andere woorden, letters, enz.vervangen.
coderen betekent iets gebruiken om iets anders weer te geven. Een codering is de verzameling regels waarmee iets van de ene representatie naar de andere wordt omgezet.
andere termen die verduidelijking verdienen in deze context:
tekenset, tekenset de tekenset die gecodeerd kan worden. “De ASCII-codering omvat een tekenset van 128 tekens.”In wezen synoniem aan “codering”. code page een” pagina ” van codes die een teken toewijzen aan een getal of bitsequentie. Ook bekend als”the table”. In wezen synoniem aan “codering”. string een string is een hoop items aan elkaar geregen. Een bit string is een aantal bits, zoals01010011. Een tekenreeks is een aantal tekens,like this. Synoniem voor “sequence”.
binair, octaal, decimaal, hex
Er zijn vele manieren om getallen te schrijven. 10011111 in binair is 237 in octaal is 159 in decimaal is 9F in hexadecimaal. Ze vertegenwoordigen allemaal dezelfde waarde, maar Hexadecimaal is korter en gemakkelijker te lezen dan binair. Ik zal vasthouden aan binair in dit artikel om het punt over beter te krijgen en bespaar de lezer een laag van abstractie. Wees niet gealarmeerd om tekencodes te zien waarnaar elders in andere notaties wordt verwezen, het is allemaal hetzelfde.
Excusez-moi?
nu we weten waar we het over hebben, laten we het gewoon zeggen: 95 karakters zijn echt niet veel als het gaat om talen. Het behandelt de basisprincipes van het Engels, maar hoe zit het met het schrijven van een gewaagde brief in het Frans? Een Straßenübergangsänderungsgesetz in het Duits? Een uitnodiging voor een smörgåsbord in het Zweeds? Dat kon je niet, niet in ASCII. Er is geen specificatie over hoe een van de letters é, ß, ü, ä, ö of å in ASCII moet worden weergegeven, dus je kunt ze niet gebruiken.
“maar kijk eens,” zeiden de Europeanen, “in een gewone computer met 8 bits per byte, verspilt ASCII een heel bit dat altijd is ingesteld op 0! We kunnen dat stukje gebruiken om een hele andere 128 waarden in die tabel te persen!”En dat deden ze. Maar toch zijn er meer dan 128 manieren om een klinker te strelen, te snijden, te snijden en te doten. Niet alle variaties van letters en kronkels die in alle Europese talen worden gebruikt, kunnen in dezelfde tabel worden weergegeven met een maximum van 256 waarden. Dus wat de wereld eindigde met een schat aan codering schema ‘ s, standaarden, de-facto standaarden en halve standaarden die allemaal betrekking hebben op een verschillende subset van tekens. Iemand moest een document over het Zweeds in het Tsjechisch schrijven, vond dat er geen codering voor beide talen bestond en vond er een uit. Ik kan me voorstellen dat het ontelbare keren is doorgegaan.
en niet te vergeten Russisch, Hindi, Arabisch, Hebreeuws, Koreaans en alle andere talen die momenteel actief worden gebruikt op deze planeet. Niet te vergeten degenen die niet meer in gebruik zijn. Zodra u het probleem van het schrijven van gemengde taal documenten in al deze talen hebt opgelost, probeer jezelf op Chinees. Of Japans. Beide bevatten tienduizenden karakters. Je hebt 256 mogelijke waarden voor een byte bestaande uit 8 bit. Ga!
multi-bytecoderingen
om een tabel te maken die karakters aan letters toewijst voor een taal die meer dan 256 karakters gebruikt, is één byte simpelweg niet genoeg. Met behulp van twee bytes (16 bits) is het mogelijk om 65.536 verschillende waarden te coderen. BIG-5 is zo ‘ n dubbele byte codering. In plaats van het breken van een reeks bits in blokken van acht, het breekt het in blokken van 16 en heeft een grote (Ik bedoel, grote) tabel die specificeert welk karakter elke combinatie van bits kaarten aan. BIG-5 in zijn basisvorm omvat meestal traditionele Chinese karakters. GB18030 is een andere codering die in wezen hetzelfde doet, maar zowel traditionele als vereenvoudigde Chinese tekens bevat. En voordat je het vraagt, ja, er zijn coderingen die alleen Vereenvoudigd Chinees dekken. Kunnen we nu niet één codering hebben?
hier een klein fragment uit de GB18030 tabel:
| bits | character |
|---|---|
10000001 01000000 |
丂 |
10000001 01000001 |
丄 |
10000001 01000010 |
丅 |
10000001 01000011 |
丆 |
10000001 01000100 |
丏 |
GB18030 covers quite a range of characters (including a large part of latin karakters), maar uiteindelijk is nog een andere gespecialiseerde codering formaat onder velen.
Unicode tot de verwarring

eindelijk had iemand genoeg van de puinhoop en begon een ring te smeden om ze allemaal te binden Maak een coderingsstandaard om alle codering te verenigen normen. Deze standaard is Unicode. Het definieert in principe een gigantische tabel van 1.114.112 Codepunten die gebruikt kunnen worden voor allerlei letters en symbolen. Dat is genoeg om alle Europese, Midden-Oosterse, verre-Oosterse, Zuidelijke, Noordelijke, Westerse, pre-historicus en toekomstige personages te coderen die de mensheid kent.2 Met behulp van Unicode, kunt u een document met vrijwel elke taal met behulp van elk teken dat u kunt typen in een computer te schrijven. Dit was ofwel onmogelijk of heel erg moeilijk te krijgen vlak voordat Unicode kwam langs. Er is zelfs een Onofficiële sectie voor Klingon in Unicode. Inderdaad, Unicode is groot genoeg om Onofficiële, privé-gebruik gebieden mogelijk te maken.
dus, hoeveel bits gebruikt Unicode om al deze tekens te coderen? Niemand. Omdat Unicode geen codering is.
verward? Veel mensen lijken dat te zijn. Unicode definieert eerst en vooral een tabel met Codepunten voor tekens. Dat is een mooie manier om te zeggen “65 staat voor A, 66 staat voor B en 9,731 staat voor ☃” (serieus, dat doet het). Hoe deze Codepunten in bits worden gecodeerd is een ander onderwerp. Om 1,114,112 verschillende waarden te vertegenwoordigen, zijn twee bytes niet genoeg. Drie bytes zijn, maar drie bytes zijn vaak lastig om mee te werken, dus vier bytes zou het comfortabele minimum zijn. Maar tenzij je Chinees gebruikt of andere karakters met grote getallen die veel bits nodig hebben om te coderen, gebruik je nooit een groot deel van die vier bytes. Als de letter “A” altijd gecodeerd was naar 00000000 00000000 00000000 01000001, “B” altijd naar 00000000 00000000 00000000 01000010 enzovoort, zou elk document opgeblazen worden tot vier keer de benodigde grootte.
om dit te optimaliseren, zijn er verschillende manieren om Unicode-Codepunten in bits te coderen. UTF-32 is zo ‘ n codering die alle Unicode-Codepunten codeert met 32 bits. Dat wil zeggen, vier bytes per karakter. Het is heel eenvoudig, maar verspilt vaak veel ruimte. UTF-16 en UTF-8 zijn coderingen met variabele lengte. Als een karakter kan worden weergegeven met een enkele byte (omdat het codepunt een heel klein getal is), zal UTF-8 het coderen met een enkele byte. Als het twee bytes vereist, zal het twee bytes etc. gebruiken. Het heeft uitgebreide manieren om de hoogste bits in een byte te gebruiken om aan te geven uit hoeveel bytes een karakter bestaat. Dit kan ruimte besparen, maar kan ook ruimte verspillen als deze signaalbits vaak moeten worden gebruikt. UTF-16 is in het midden, met behulp van ten minste twee bytes, groeien tot maximaal vier bytes indien nodig.
| character | encoding | bits |
|---|---|---|
| A | UTF-8 | 01000001 |
| A | UTF-16 | 00000000 01000001 |
| A | UTF-32 | 00000000 00000000 00000000 01000001 |
| あ | UTF-8 | 11100011 10000001 10000010 |
| あ | UTF-16 | 00110000 01000010 |
| あ | UTF-32 | 00000000 00000000 00110000 01000010 |
en dat is alles. Unicode is een grote tabel die tekens toewijst aan getallen en de verschillende UTF-coderingen specificeren hoe deze getallen als bits worden gecodeerd. Over het algemeen is Unicode nog een ander coderingsschema. Er is niets speciaals aan, het is gewoon proberen om alles te bedekken terwijl het nog steeds efficiënt is. En dat is een goede zaak.™
Codepunten
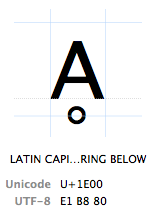
tekens worden aangeduid met hun “Unicode-codepunt”. Unicode-Codepunten worden in hexadecimaal geschreven (om de getallen korter te houden), voorafgegaan door een “U+” (dat is precies wat ze doen, het heeft geen andere betekenis Dan “Dit is een Unicode-codepunt”). Het teken Ḁ heeft het Unicode-codepunt U + 1E00. In andere (decimale) woorden, het is het 7680e teken van de Unicode tabel. Het wordt officieel “Latijnse hoofdletter A met RING hieronder” genoemd.
TL; DR
een samenvatting van al het bovenstaande: elk teken kan worden gecodeerd in veel verschillende bitsequenties en elke specifieke bitsequentie kan veel verschillende tekens vertegenwoordigen, afhankelijk van welke codering wordt gebruikt om ze te lezen of te schrijven. De reden is simpelweg omdat verschillende coderingen verschillende aantallen bits per karakters en verschillende waarden gebruiken om verschillende karakters te vertegenwoordigen.
| bits | encoding | characters |
|---|---|---|
11000100 01000010 |
Windows Latin 1 | ÄB |
11000100 01000010 |
Mac Roman | ƒB |
11000100 01000010 |
GB18030 | 腂 |
| characters | encoding | bits |
|---|---|---|
| Føö | Windows Latin 1 | 01000110 11111000 11110110 |
| Føö | Mac Roman | 01000110 10111111 10011010 |
| Føö | UTF-8 | 01000110 11000011 10111000 11000011 10110110 |
Misverstanden, verwarring en problemen
dit alles gezegd zijnde, we komen om de problemen ervaren door veel gebruikers en programmeurs elke dag, hoe deze problemen hebben betrekking op al het bovenstaande en wat hun oplossing is. Het grootste probleem is:
Waarom zijn mijn karakters in godsnaam vervormd?!
ÉGÉìÉRÅ;als die $string in een enkele byte-codering zat, zou dit ons het eerste teken geven. Maar alleen omdat ” character “samenvalt met” byte ” in een single-byte codering. PHP geeft ons gewoon de eerste byte zonder na te denken over “karakters”. Strings zijn byte sequenties naar PHP, niets meer, niets minder. Al dit” leesbare karakter ” gedoe is een menselijk ding en PHP geeft er niet om.
01000100 01101111 01101110 00100111 01110100D o n ' t01100011 01100001 01110010 01100101 00100001c a r e !hetzelfde geldt voor veel standaardfuncties zoals substrstrpostrim enzovoort. De niet-ondersteuning ontstaat als er een discrepantie is tussen de lengte van een byte en een karakter.
11100110 10111100 10100010 11100101 10101101 10010111漢 字
door gebruik te maken van $string op de bovenstaande tekenreeks geven we opnieuw de eerste byte, die 11100110is. Met andere woorden, een derde van het drie-byte karakter “漢”. 11100110 is op zichzelf een ongeldige UTF-8-reeks, dus de tekenreeks is nu verbroken. Als u daar zin in hebt, kunt u proberen dat te interpreteren in een andere codering waar 11100110 Een geldig teken vertegenwoordigt, wat zal resulteren in een willekeurig teken. Veel plezier, maar gebruik het niet in de productie.
en dat is eigenlijk alles wat er is. “PHP ondersteunt niet native Unicode” betekent gewoon dat de meeste PHP functies aannemen één byte = één teken, wat kan leiden tot het hakken van multi-byte tekens in de helft of het berekenen van de lengte van strings verkeerd als je naïef gebruik maakt van niet-multi-byte-aware functies op multi-byte strings. Het betekent niet dat je Unicode niet kunt gebruiken in PHP of dat elke Unicode string gezegend moet worden met utf8_encode of andere dergelijke onzin.
gelukkig is er de Multibyte String extensie, die alle belangrijke string functies repliceert op een multi-byte bewuste manier. Het gebruik van mb_substr($string, 0, 1, 'UTF-8') op de bovenstaande tekenreeks geeft correct 11100110 10111100 10100010, wat het hele” 漢 ” teken is. Omdat de mb_ functies nu echt moeten nadenken over wat ze doen, moeten ze weten aan welke codering ze werken. Daarom accepteert elke mb_functie ook een $encoding parameter. Als alternatief kan dit globaal worden ingesteld voor alle mb_ functies met behulp van .
het gebruik en misbruik van PHP ’s afhandeling van coderingen
het hele probleem van PHP’ s (niet-)ondersteuning voor Unicode is dat het het gewoon niet uitmaakt. Strings zijn byte sequenties naar PHP. Welke bytes in het bijzonder maakt niet uit. PHP doet niets met strings behalve het houden van hen opgeslagen in het geheugen. PHP heeft gewoon geen concept van zowel karakters of coderingen. En tenzij het probeert strings te manipuleren, hoeft het dat ook niet te doen; het houdt gewoon bytes vast die wel of niet uiteindelijk door iemand anders als karakters worden geïnterpreteerd. De enige vereiste die PHP heeft aan coderingen is dat PHP broncode moet worden opgeslagen in een ASCII compatibele codering. De PHP parser is op zoek naar bepaalde tekens die het vertellen wat te doen. $00100100) geeft het begin van een variabele aan, =00111101) een toewijzing, "00100010) het begin en einde van een string enzovoort. Iets anders dat geen speciale betekenis heeft voor de parser wordt gewoon genomen als een letterlijke byte volgorde. Dat omvat alles tussen aanhalingstekens, zoals hierboven besproken. Dit betekent het volgende:
-
U kunt PHP broncode niet opslaan in een ASCII-incompatibele codering. Bijvoorbeeld, in UTF-16 wordt a
"gecodeerd als00000000 00100010. Voor PHP, dat alles als ASCII probeert te lezen, is dat eenNULbyte gevolgd door een".PHP zal waarschijnlijk een hik krijgen als elk ander teken dat het vindt eenNULbyte is. -
U kunt PHP-broncode opslaan in elke ASCII-compatibele codering. Als de eerste 128 Codepunten van een codering identiek zijn aan ASCII, kan PHP het ontleden. Alle karakters die op welke manier dan ook belangrijk zijn voor PHP zijn binnen de 128 Codepunten gedefinieerd door ASCII. Als string literals bevatten enige code punten verder dan dat, PHP maakt het niet uit. U kunt PHP sourcecode opslaan in ISO-8859-1, Mac Roman, UTF-8 of een andere ASCII-compatibele codering. De string literals in uw script zal hebben welke codering u uw broncode opgeslagen als.
-
elk extern bestand dat u verwerkt met PHP kan in elke gewenste codering staan. Als PHP het niet hoeft te ontleden, zijn er geen vereisten om te voldoen aan de PHP parser tevreden te houden.
$foo = file_get_contents('bar.txt');het bovenstaande leest de bits in
bar.txtin de variabele$foo. PHP probeert niet om de inhoud te interpreteren,converteren, coderen of op een andere manier te knoeien met de inhoud. Het bestand kan zelfs binaire gegevens bevatten,zoals een afbeelding, PHP maakt het niet uit. -
als interne en externe coderingen moeten overeenkomen, moeten ze overeenkomen. Een veelvoorkomend geval is lokalisatie, waar de broncode iets bevat als
echo localize('Foobar')en een extern lokalisatiebestand iets in de trant van dit bevat:msgid "Foobar"msgstr "フーバー"beide” Foobar ” strings moeten een identieke bit representatie hebben als u de juiste lokalisatie wilt vinden.Als de broncode was opgeslagen in ASCII maar het lokalisatiebestand in UTF-16, zouden de strings niet overeenkomen.Ofwel een soort van codering conversie nodig zou zijn of het gebruik van een encoding-aware string matching functie.
de scherpzinnige lezer zou op dit moment kunnen vragen of het mogelijk is om een UTF-16 byte-reeks op te slaan in een string-letterlijke van een ASCII-gecodeerd broncodebestand, waarop het antwoord zou zijn: absoluut.
echo "UTF-16";Als u uw teksteditor kunt meenemen om de echo " en "; delen in ASCII op te slaan en alleen UTF-16 in UTF-16, zal dit prima werken. De noodzakelijke binaire representatie daarvoor ziet er zo uit:
01100101 01100011 01101000 01101111 00100000 00100010e c h o "11111110 11111111 00000000 01010101 00000000 01010100(UTF-16 marker) U T00000000 01000110 00000000 00101101 00000000 00110001F - 100000000 00110110 00100010 001110116 " ;de eerste regel en de laatste twee bytes zijn ASCII. De rest is UTF-16 met twee bytes per karakter. De leidende 11111110 11111111 op Regel 2 is een marker die vereist is aan het begin van UTF-16 gecodeerde tekst (vereist door de UTF-16 standaard, PHP geeft er geen donder om). Dit PHP script zal gelukkig de string “UTF-16” gecodeerd in UTF-16, omdat het eenvoudig de bytes tussen de twee dubbele aanhalingstekens, die toevallig de tekst “UTF-16” gecodeerd in UTF-16 vertegenwoordigen. Het broncodebestand is echter noch volledig geldig ASCII noch UTF-16, dus het werken met het in een teksteditor zal niet zo leuk zijn.
Bottom line
PHP ondersteunt Unicode, of in feite elke codering, prima, zolang aan bepaalde vereisten wordt voldaan om de parser tevreden te houden en de programmeur weet wat hij doet. Je hoeft echt alleen maar voorzichtig te zijn bij het manipuleren van tekenreeksen, waaronder snijden, trimmen, tellen en andere bewerkingen die moeten gebeuren op een karakterniveau in plaats van een byte-niveau. Als je niet” iets “doet met je strings naast het lezen en uitvoeren ervan, zul je nauwelijks problemen hebben met PHP’ s ondersteuning van coderingen die je ook niet in een andere taal zou hebben.
encoding-aware languages
wat betekent het dan dat een taal Unicode ondersteunt? Javascript ondersteunt bijvoorbeeld Unicode. In feite is elke string in Javascript UTF-16 gecodeerd. In feite is het het enige waar Javascript mee te maken heeft. U kunt geen string in Javascript hebben die niet UTF-16 gecodeerd is. Javascript aanbidt Unicode in de mate dat er geen mogelijkheid om te gaan met een andere codering in de kerntaal. Aangezien Javascript meestal wordt uitgevoerd in een browser dat is geen probleem, omdat de browser kan omgaan met de alledaagse logistiek van het coderen en decoderen input en output.
andere talen zijn gewoon encoding-aware. Intern slaan ze strings op in een bepaalde codering, vaak UTF-16. Op hun beurt moeten ze worden verteld of proberen om de codering van alles wat te maken heeft met tekst te detecteren. Ze moeten weten in welke codering de broncode is opgeslagen, in welke codering een bestand ze geacht worden te lezen is, in welke codering je tekst wilt uitvoeren; en ze converteren coderingen op de vlieg als dat nodig is met enige manifestatie van Unicode als de tussenpersoon. Ze doen hetzelfde wat je in PHP semi-automatisch achter de schermen kunt/moet/moeten doen. Dat is niet beter of slechter dan PHP, gewoon anders. Het leuke aan het is dat standaard taalfuncties die zich bezighouden met strings Just Work™, terwijl in PHP men wat aandacht moet sparen aan de vraag of een string multi-byte tekens kan bevatten of niet en kies string manipulatie functies dienovereenkomstig.
de dieptes van Unicode
omdat Unicode veel verschillende scripts en veel verschillende problemen behandelt, heeft het veel diepte. De Unicode-standaard bevat bijvoorbeeld informatie voor problemen zoals CJK ideograph unification. Dat betekent, informatie dat twee of meer Chinese/Japanse/Koreaanse karakters eigenlijk hetzelfde karakter vertegenwoordigen in iets verschillende schrijfmethoden. Of regels over het omzetten van kleine letters naar hoofdletters, vice versa en retour, wat niet altijd zo eenvoudig is in alle scripts als in de meeste West-Europese Latijnse scripts. Sommige tekens kunnen ook worden weergegeven met behulp van verschillende Codepunten. De letter “ö” kan bijvoorbeeld worden weergegeven met behulp van het codepunt U+00F6 (“Latijnse kleine LETTER O met trema”) of als de twee Codepunten U+006F (“Latijnse kleine LETTER O”) en U+0308 (“trema combineren”), dat is de letter “o” gecombineerd met “”. In UTF-8 is dat ofwel de dubbele bytenreeks 11000011 10110110 of de drie bytenreeks 01101111 11001100 10001000, die beide hetzelfde leesbare karakter vertegenwoordigen. Als zodanig zijn er regels voor normalisatie binnen de Unicode-standaard, dat wil zeggen hoe een van deze formulieren kan worden omgezet in de andere. Dit en nog veel meer valt buiten het toepassingsgebied van dit artikel, maar men moet zich ervan bewust zijn.
Final TL; DR
- tekst is altijd een reeks bits die moet worden vertaald in voor mensen leesbare tekst met behulp van opzoektabellen. Als de verkeerde opzoektabel wordt gebruikt, wordt het verkeerde teken gebruikt.
- je hebt eigenlijk nooit direct te maken met” karakters “of” text”, je hebt altijd te maken met bits Zoals Gezien door meerdere lagen van abstracties. Onjuiste resultaten zijn een teken dat een van de abstractielagen faalt.
- als twee systemen met elkaar praten, moeten ze altijd specificeren in welke codering ze met elkaar willen praten. Het eenvoudigste voorbeeld hiervan is deze website die uw browser vertelt dat het is gecodeerd in UTF-8.
- in deze tijd is de standaardcodering UTF-8, omdat het vrijwel elk karakter van belang kan coderen, achterwaarts compatibel is met de de-facto baseline ASCII en toch relatief ruimte-efficiënt is voor de meeste use cases.
- andere coderingen hebben nog af en toe hun nut, maar u zou een concrete reden moeten hebben om de hoofdpijnen te willen behandelen die geassocieerd zijn met tekensets die alleen een subset van Unicode kunnen coderen.
- De dagen van één byte = één karakter zijn voorbij en zowel programmeurs als programma ‘ s moeten dit inhalen.
nu zou je echt geen excuus meer moeten hebben de volgende keer dat je wat tekst door elkaar haalt.
-
Ja, dat betekent dat ASCII kan worden opgeslagen en overgedragen met slechts 7 bits en dat is het vaak. Nee, dit valt niet binnen de reikwijdte van dit artikel en omwille van het argument zullen we aannemen dat het hoogste bit “verspild” is in ASCII. ↩
-
en als dat niet het geval is, wordt het uitgebreid. Dat is al een paar keer gebeurd. ↩
-
houd er rekening mee dat wanneer ik de term “starting” samen met “byte” gebruik, ik het bedoel vanuit een voor mensen leesbaar oogpunt. ↩
-
Gebruik de UTF-8 specificatie als u dit met pen en papier wilt volgen. ↩
-
Hey, Ik ben een programmeur, geen bioloog. ↩
-
en natuurlijk zal er geen recente back-up zijn. ↩
-
een “Unicode-teken” is een codepunt in de Unicode-tabel. “あ” is geen Unicode karakter, het is de Hiragana letter あ. Er is een Unicode code punt voor, maar dat maakt de letter zelf niet een Unicode karakter. Een “UTF-8 karakter”is een oxymoron, maar kan worden uitgerekt tot wat technisch een “UTF-8 sequentie” wordt genoemd, dat is een byte sequentie van een, twee, drie of vier bytes die een Unicode karakter vertegenwoordigen. Beide termen worden vaak gebruikt in de zin van “elke letter die geen deel uitmaakt van mijn toetsenbord”, wat absoluut niets betekent. ↩
-
http://www.php.net/manual/en/function.utf8-encode.php ↩
over de auteur
David C. Zentgraf is een webontwikkelaar die deels in Japan en Europa werkt en regelmatig werkt op Stack Overflow.Als je feedback, kritiek of toevoegingen hebt, aarzel dan niet om @deceze te proberen op Twitter,neem een gefundeerde gok op zijn e-mailadres of zoek het op met behulp van aloude methoden.Dit artikel werd gepubliceerd op kunststube.net en nee, er is geen vies woord in “Kunststube”.