Was jeder Programmierer absolut, positiv über Kodierungen und Zeichensätze wissen muss, um mit Text zu arbeiten
Wenn Sie mit Text in einem Computer zu tun haben, müssen Sie über Kodierungen wissen. Zeitraum. Ja, auch wenn Sie nur E-Mails senden. Auch wenn Sie nur E-Mails erhalten. Sie müssen nicht jedes Detail verstehen, aber Sie müssen zumindest wissen, worum es bei dieser ganzen „Codierung“ geht. Und die gute Nachricht zuerst: während das Thema chaotisch und verwirrend werden kann, ist die Grundidee wirklich, wirklich einfach.
Dieser Artikel behandelt Kodierungen und Zeichensätze. Ein Artikel von Joel Spolsky mit dem Titel Das absolute Minimum, das jeder Softwareentwickler unbedingt über Unicode und Zeichensätze wissen muss (keine Ausreden!) ist eine schöne Einführung in das Thema und ich genieße es sehr, es ab und zu zu lesen. Ich zögere, Leute darauf zu verweisen, die Probleme haben, Codierungsprobleme zu verstehen, da es zwar unterhaltsam ist, aber die tatsächlichen technischen Details ziemlich leicht sind. Ich hoffe, dieser Artikel kann etwas mehr Licht darauf werfen, was genau eine Codierung ist und warum all Ihr Text vermasselt wird, wenn Sie ihn am wenigsten brauchen. Dieser Artikel richtet sich an Entwickler (mit Schwerpunkt PHP), aber jeder Computerbenutzer sollte davon profitieren können.
Die Grundlagen klarstellen
Jeder ist sich dessen auf einer gewissen Ebene bewusst, aber irgendwie scheint dieses Wissen plötzlich in einer Diskussion über Text zu verschwinden, also lasst es uns zuerst herausfinden: Ein Computer kann keine „Buchstaben“, „Zahlen“, „Bilder“ oder irgendetwas anderes speichern. Das einzige, was es speichern und arbeiten kann, sind Bits. Ein Bit kann nur zwei Werte haben: yes oder notrue oder false1 oder 0 oder wie auch immer Sie diese beiden Werte sonst nennen möchten. Da ein Computer mit Elektrizität arbeitet, ist ein „tatsächliches“ Bit ein Stromstoß, der entweder vorhanden ist oder nicht vorhanden ist. Für Menschen wird dies normalerweise mit 1 und 0 und ich werde mich in diesem Artikel an diese Konvention halten.
Um Bits zu verwenden, um überhaupt etwas außer Bits darzustellen, brauchen wir Regeln. Wir müssen eine Folge von Bits mithilfe eines Codierungsschemas oder kurz Codierung in Buchstaben, Zahlen und Bilder konvertieren. So:
01100010 01101001 01110100 01110011b i t sIn dieser Codierung steht 01100010 für den Buchstaben „b“, 01101001 für den Buchstaben „i“, 01110100 für „t“ und 01110011 für „s“. Eine bestimmte Bitfolge steht für einen Buchstaben und ein Buchstabe für eine bestimmte Bitfolge. Wenn Sie dies für 26 Buchstaben im Kopf behalten können oder sehr schnell in einer Tabelle nachschlagen, können Sie Bits wie ein Buch lesen.
Das obige Kodierungsschema ist zufällig ASCII. Eine Zeichenfolge von 1s und 0s wird in Teile von jeweils acht Bit (kurz ein Byte) zerlegt. Die ASCII-Codierung gibt eine Tabelle an, die Bytes in lesbare Buchstaben übersetzt. Hier ist ein kurzer Auszug aus dieser Tabelle:
| bits | character |
|---|---|
01000001 |
A |
01000010 |
B |
01000011 |
C |
01000100 |
D |
01000101 |
E |
01000110 |
F |
There are 95 human readable in der ASCII-Tabelle angegebene Zeichen, einschließlich der Buchstaben A bis Z in Groß- und Kleinbuchstaben, der Zahlen 0 bis 9, einer Handvoll Satzzeichen und Zeichen wie dem Dollarzeichen, dem kaufmännischen und einigen anderen. Es enthält auch 33 Werte für Dinge wie Leerzeichen, Zeilenvorschub, Tabulator, Rücktaste und so weiter. Diese sind per se nicht druckbar, aber in irgendeiner Form sichtbar und für den Menschen direkt nützlich. Eine Reihe von Werten sind nur für einen Computer nützlich, z. B. Codes, die den Anfang oder das Ende eines Textes anzeigen. Insgesamt sind in der ASCII-Codierung 128 Zeichen definiert, was eine schöne runde Zahl ist (für Leute, die mit Computern zu tun haben), da sie alle möglichen Kombinationen von 7 Bits verwendet (000000000000010000010 durch 1111111).1
Und da haben Sie es, die Möglichkeit, lesbaren Text nur mit 1s und 0s darzustellen.
01001000 01100101 01101100 01101100 01101111 00100000 01010111 01101111 01110010 01101100 01100100„Hallo Welt“
Wichtige Begriffe
Um etwas in ASCII zu codieren, folgen Sie der Tabelle von rechts nach links und ersetzen Sie Bits durch Buchstaben. Um eine Bitfolge in lesbare Zeichen zu dekodieren, folgen Sie der Tabelle von links nach rechts und ersetzen Sie Buchstaben durch Bits.
kodieren |enˈkōd|
verb
in eine kodierte Form umwandelncode |kōd|
Substantiv
ein System von Wörtern, Buchstaben, Zahlen oder anderen Symbolen, die andere Wörter, Buchstaben usw. ersetzen.
Kodieren bedeutet, etwas zu verwenden, um etwas anderes darzustellen. Eine Codierung ist der Satz von Regeln, mit denen etwas von einer Darstellung in eine andere konvertiert werden kann.
Weitere Begriffe, die in diesem Zusammenhang eine Klarstellung verdienen:
Zeichensatz, Zeichensatz Die Menge der Zeichen, die codiert werden können. „Die ASCII-Codierung umfasst einen Zeichensatz von 128 Zeichen.“ Im Wesentlichen gleichbedeutend mit „Codierung“. codepage Eine „Seite“ von Codes, die ein Zeichen einer Zahl oder Bitfolge zuordnen. A.k.a. „der Tisch“. Im Wesentlichen gleichbedeutend mit „Codierung“. string Ein String ist ein Bündel von Elementen, die aneinandergereiht sind. Eine Bitfolge ist eine Reihe von Bits, wie
01010011. Eine Zeichenfolge besteht aus einer Reihe von Zeichen,like this. Gleichbedeutend mit „Sequenz“.
Binär, oktal, dezimal, hex
Es gibt viele Möglichkeiten, Zahlen zu schreiben. 10011111 in binär ist 237 in oktal ist 159 in dezimal ist 9F in hexadezimal. Sie alle repräsentieren den gleichen Wert, aber hexadezimal ist kürzer und einfacher zu lesen als binär. Ich werde in diesem Artikel bei Binary bleiben, um den Punkt besser zu vermitteln und dem Leser eine Abstraktionsebene zu ersparen. Do not be alarmed to see character codes referred to in other notations elsewhere, it’s all the same thing.
Excusez-moi?
Now that we know what we’re talking about, let’s just say it: 95 characters really isn’t a lot when it comes to languages. It covers the basics of English, but what about writing a risqué letter in French? A Straßenübergangsänderungsgesetz in German? An invitation to a smörgåsbord in Swedish? Well, you couldn’t. Not in ASCII. There’s no specification on how to represent any of the letters é, ß, ü, ä, ö or å in ASCII, so you can’t use them.
„Aber sieh es dir an“, sagten die Europäer, „in einem gewöhnlichen Computer mit 8 Bits pro Byte verschwendet ASCII ein ganzes Bit, das immer auf 0 ! Wir können dieses Bit verwenden, um weitere 128 Werte in diese Tabelle zu quetschen!“ Und so taten sie es. Trotzdem gibt es mehr als 128 Möglichkeiten, einen Vokal zu streichen, zu schneiden, zu schneiden und zu punktieren. Nicht alle Variationen von Buchstaben und Schnörkeln, die in allen europäischen Sprachen verwendet werden, können in derselben Tabelle mit maximal 256 Werten dargestellt werden. Die Welt hat also eine Fülle von Codierungsschemata, Standards, De-facto-Standards und Halbstandards, die alle eine andere Teilmenge von Zeichen abdecken. Jemand musste ein Dokument über Schwedisch auf Tschechisch schreiben, stellte fest, dass keine Kodierung beide Sprachen abdeckte und erfand eine. Oder so stelle ich mir vor, es ging unzählige Male vorbei.
Und nicht zu vergessen Russisch, Hindi, Arabisch, Hebräisch, Koreanisch und all die anderen Sprachen, die derzeit auf diesem Planeten aktiv sind. Ganz zu schweigen von denen, die nicht mehr verwendet werden. Sobald Sie das Problem gelöst haben, wie Sie Dokumente in gemischten Sprachen in all diesen Sprachen schreiben, versuchen Sie sich auf Chinesisch. Oder Japanisch. Beide enthalten Zehntausende von Zeichen. Sie haben 256 mögliche Werte für ein Byte, das aus 8 Bit besteht. Los!
Multibyte-Codierungen
Um eine Tabelle zu erstellen, die Zeichen Buchstaben für eine Sprache zuordnet, die mehr als 256 Zeichen verwendet, reicht ein Byte einfach nicht aus. Mit zwei Bytes (16 Bit) können 65.536 verschiedene Werte codiert werden. BIG-5 ist eine solche Doppelbyte-Codierung. Anstatt eine Zeichenfolge von Bits in Blöcke von acht zu zerlegen, wird sie in Blöcke von 16 aufgeteilt und es gibt eine große (ich meine, große) Tabelle, die angibt, welchem Zeichen jede Kombination von Bits zugeordnet ist. BIG-5 umfasst in seiner Grundform hauptsächlich traditionelle chinesische Schriftzeichen. GB18030 ist eine weitere Codierung, die im Wesentlichen dasselbe tut, aber sowohl traditionelle als auch vereinfachte chinesische Schriftzeichen enthält. Und bevor Sie fragen, ja, es gibt Kodierungen, die nur vereinfachtes Chinesisch abdecken. Wir können jetzt nicht nur eine Codierung haben, oder?
Hier ein kleiner Auszug aus der GB18030 Tabelle:
| bits | character |
|---|---|
10000001 01000000 |
丂 |
10000001 01000001 |
丄 |
10000001 01000010 |
丅 |
10000001 01000011 |
丆 |
10000001 01000100 |
丏 |
GB18030 covers quite a range of characters (including a large part of latin zeichen), aber am Ende ist noch ein anderes spezialisiertes Codierungsformat unter vielen.
Unicode zur Verwirrung

Endlich hatte jemand genug von dem Durcheinander und machte sich daran, einen Ring zu schmieden, um sie alle zu binden Erstellen Sie einen Codierungsstandard, um alle Codierungen zu vereinheitlichen normen. Dieser Standard ist Unicode. Es definiert im Grunde eine riesige Tabelle von 1.114.112 Codepunkten, die für alle Arten von Buchstaben und Symbolen verwendet werden können. Das ist viel, um alle europäischen, nahöstlichen, fernöstlichen, südlichen, nördlichen, westlichen, vorgeschichtlichen und zukünftigen Charaktere zu kodieren, die die Menschheit kennt.2 Mit Unicode können Sie ein Dokument schreiben, das praktisch jede Sprache enthält, indem Sie ein beliebiges Zeichen verwenden, das Sie in einen Computer eingeben können. Dies war entweder unmöglich oder sehr, sehr schwer zu bekommen, bevor Unicode kam. Es gibt sogar einen inoffiziellen Abschnitt für Klingonisch in Unicode. In der Tat ist Unicode groß genug, um inoffizielle Bereiche für den privaten Gebrauch zuzulassen.
Also, wie viele Bits verwendet Unicode, um all diese Zeichen zu codieren? Kein. Weil Unicode keine Codierung ist.
Verwirrt? Viele Menschen scheinen es zu sein. Unicode definiert in erster Linie eine Tabelle von Codepunkten für Zeichen. Das ist eine ausgefallene Art zu sagen „65 steht für A, 66 steht für B und 9.731 steht für ☃“ (im Ernst, das tut es). Wie diese Codepunkte tatsächlich in Bits codiert werden, ist ein anderes Thema. Um 1.114.112 verschiedene Werte darzustellen, reichen zwei Bytes nicht aus. Drei Bytes sind, aber drei Bytes sind oft umständlich zu arbeiten, also wären vier Bytes das komfortable Minimum. Aber wenn Sie nicht tatsächlich Chinesisch oder einige der anderen Zeichen mit großen Zahlen verwenden, deren Codierung viele Bits erfordert, werden Sie niemals einen großen Teil dieser vier Bytes verwenden. Wenn der Buchstabe „A“ immer in 00000000 00000000 00000000 01000001, „B“ immer in 00000000 00000000 00000000 01000010 usw. codiert wäre, würde sich jedes Dokument auf das Vierfache der erforderlichen Größe aufblähen.
Um dies zu optimieren, gibt es mehrere Möglichkeiten, Unicode-Codepunkte in Bits zu codieren. UTF-32 ist eine solche Codierung, die alle Unicode-Codepunkte mit 32 Bit codiert. Das heißt, vier Bytes pro Zeichen. Es ist sehr einfach, verschwendet aber oft viel Platz. UTF-16 und UTF-8 sind Kodierungen variabler Länge. Wenn ein Zeichen mit einem einzelnen Byte dargestellt werden kann (da sein Codepunkt eine sehr kleine Zahl ist), wird UTF-8 es mit einem einzelnen Byte codieren. Wenn es zwei Bytes benötigt, werden zwei Bytes usw. verwendet. Es gibt ausgeklügelte Möglichkeiten, die höchsten Bits in einem Byte zu verwenden, um zu signalisieren, aus wie vielen Bytes ein Zeichen besteht. Dies kann Platz sparen, kann aber auch Platz verschwenden, wenn diese Signalbits häufig verwendet werden müssen. UTF-16 befindet sich in der Mitte, verwendet mindestens zwei Bytes und wächst bei Bedarf auf bis zu vier Bytes.
| character | encoding | bits |
|---|---|---|
| A | UTF-8 | 01000001 |
| A | UTF-16 | 00000000 01000001 |
| A | UTF-32 | 00000000 00000000 00000000 01000001 |
| あ | UTF-8 | 11100011 10000001 10000010 |
| あ | UTF-16 | 00110000 01000010 |
| あ | UTF-32 | 00000000 00000000 00110000 01000010 |
Und das ist alles. Unicode ist eine große Tabelle, die Zeichen Zahlen zuordnet, und die verschiedenen UTF-Codierungen geben an, wie diese Zahlen als Bits codiert werden. Insgesamt ist Unicode ein weiteres Codierungsschema. Es ist nichts Besonderes daran, es wird nur versucht, alles abzudecken und gleichzeitig effizient zu sein. Und das ist gut so.™
Codepunkte
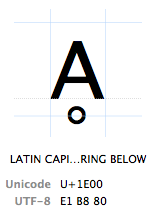
Zeichen werden durch ihren „Unicode-Codepunkt“ bezeichnet. Unicode-Codepunkte werden hexadezimal geschrieben (um die Zahlen kürzer zu halten), gefolgt von einem „U +“ (genau das tun sie, es hat keine andere Bedeutung als „Dies ist ein Unicode-Codepunkt“). Das Zeichen Ḁ hat den Unicode-Codepunkt U+1E00. Mit anderen Worten (dezimal) ist es das 7680ste Zeichen der Unicode-Tabelle. Es heißt offiziell „LATEINISCHER GROßBUCHSTABE A MIT RING DARUNTER“.
TL; DR
Eine Zusammenfassung aller oben genannten Punkte: Jedes Zeichen kann in vielen verschiedenen Bitfolgen codiert werden, und jede bestimmte Bitfolge kann viele verschiedene Zeichen darstellen, je nachdem, welche Codierung zum Lesen oder Schreiben verwendet wird. Der Grund liegt einfach darin, dass unterschiedliche Codierungen unterschiedliche Bitzahlen pro Zeichen und unterschiedliche Werte verwenden, um unterschiedliche Zeichen darzustellen.
| bits | encoding | characters |
|---|---|---|
11000100 01000010 |
Windows Latin 1 | ÄB |
11000100 01000010 |
Mac Roman | ƒB |
11000100 01000010 |
GB18030 | 腂 |
| characters | encoding | bits |
|---|---|---|
| Føö | Windows Latein 1 | 01000110 11111000 11110110 |
| Føö | Mac Roman | 01000110 10111111 10011010 |
| Føö | UTF-8 | 01000110 11000011 10111000 11000011 10110110 |
Missverständnisse, Verwirrungen und Probleme
Nachdem wir all das gesagt haben, kommen wir zu den tatsächlichen Problemen, die viele Benutzer und Programmierer jeden Tag erleben, wie sich diese Probleme auf all das beziehen und was ihre Lösung ist. Das größte Problem von allen ist:
Warum in Gottes Namen sind meine Charaktere verstümmelt?!
ÉGÉìÉRÅ;Wenn das $string in einer Einzelbyte-Codierung wäre, würde dies uns das erste Zeichen geben. Aber nur, weil „Zeichen“ in einer Einzelbyte-Codierung mit „Byte“ übereinstimmt. PHP gibt uns einfach das erste Byte, ohne an „Zeichen“ zu denken. Strings sind Byte-Sequenzen zu PHP, nicht mehr, nicht weniger. All dieses „lesbare Zeichen“ -Zeug ist eine menschliche Sache und PHP kümmert sich nicht darum.
01000100 01101111 01101110 00100111 01110100D o n ' t01100011 01100001 01110010 01100101 00100001c a r e !Das gleiche gilt für viele Standardfunktionen wie substrstrpostrim und so weiter. Die Nichtunterstützung tritt auf, wenn eine Diskrepanz zwischen der Länge eines Bytes und eines Zeichens besteht.
11100110 10111100 10100010 11100101 10101101 10010111漢 字
Wenn Sie $string in der obigen Zeichenfolge verwenden, erhalten wir wiederum das erste Byte, das 11100110 . Mit anderen Worten, ein Drittel des Drei-Byte-Zeichens „漢“. 11100110 ist an sich eine ungültige UTF-8-Sequenz, daher ist die Zeichenfolge jetzt unterbrochen. Wenn Sie Lust dazu haben, können Sie versuchen, dies in einer anderen Codierung zu interpretieren, in der 11100110 ein gültiges Zeichen darstellt, was zu einem zufälligen Zeichen führt. Viel Spaß, aber verwenden Sie es nicht in der Produktion.
Und das ist eigentlich alles. „PHP unterstützt Unicode nicht nativ“ bedeutet einfach, dass die meisten PHP-Funktionen ein Byte = ein Zeichen annehmen, was dazu führen kann, dass Multibyte-Zeichen halbiert oder die Länge von Zeichenfolgen falsch berechnet werden, wenn Sie naiv nicht-Multibyte-fähige Funktionen für Multibyte-Zeichenfolgen verwenden. Dies bedeutet nicht, dass Sie Unicode in PHP nicht verwenden können oder dass jede Unicode-Zeichenfolge mit utf8_encode oder anderem Unsinn gesegnet werden muss.
Zum Glück gibt es die Multibyte-String-Erweiterung, die alle wichtigen String-Funktionen multibyte-fähig repliziert. Die Verwendung von mb_substr($string, 0, 1, 'UTF-8') in der obigen Zeichenfolge gibt korrekt 11100110 10111100 10100010 zurück, was das gesamte „漢“ -Zeichen ist. Da die mb_ -Funktionen jetzt tatsächlich darüber nachdenken müssen, was sie tun, müssen sie wissen, an welcher Codierung sie arbeiten. Daher akzeptiert jede mb_ Funktion auch einen $encoding Parameter. Alternativ kann dies global für alle mb_ Funktionen mit mb_internal_encoding gesetzt werden.
Verwenden und Missbrauchen von PHP’s Umgang mit Codierungen
Das ganze Problem von PHP’s (Nicht-)Unterstützung für Unicode ist, dass es einfach egal ist. Strings sind Byte-Sequenzen zu PHP. Was genau passiert, spielt keine Rolle. PHP macht nichts mit Strings, außer sie im Speicher zu speichern. PHP hat einfach kein Konzept von Zeichen oder Kodierungen. Und wenn es nicht versucht, Zeichenfolgen zu manipulieren, muss es auch nicht; Es hält nur Bytes fest, die möglicherweise von jemand anderem als Zeichen interpretiert werden oder nicht. Die einzige Anforderung, die PHP an Codierungen hat, ist, dass der PHP-Quellcode in einer ASCII-kompatiblen Codierung gespeichert werden muss. Der PHP-Parser sucht nach bestimmten Zeichen, die ihm sagen, was zu tun ist. $00100100) signalisiert den Start einer Variablen, =00111101) eine Zuweisung, "00100010) der Anfang und das Ende eines Strings und so weiter. Alles andere, was für den Parser keine besondere Bedeutung hat, wird nur als literale Bytesequenz verwendet. Das schließt alles zwischen Anführungszeichen ein, wie oben besprochen. Dies bedeutet Folgendes:
-
Sie können PHP-Quellcode nicht in einer ASCII-inkompatiblen Codierung speichern. Zum Beispiel ist in UTF-16 a
"codiertals00000000 00100010. Für PHP, das versucht, alles als ASCII zu lesen, ist das einNULByte gefolgt von einem".PHP wird wahrscheinlich einen Schluckauf bekommen, wenn jedes andere gefundene Zeichen einNULByte ist. -
Sie können PHP-Quellcode in jeder ASCII-kompatiblen Codierung speichern. Wenn die ersten 128 Codepunkte einer Codierung sindidentisch zu ASCII, kann PHP es analysieren. Alle Zeichen, die für PHP in irgendeiner Weise von Bedeutung sind, befinden sich innerhalb der 128 von ASCII definierten Codepunkte. Wenn String-Literale darüber hinaus Codepunkte enthalten, ist es PHP egal. Sie können PHP-Quellcode in ISO-8859-1, Mac Os, UTF-8 oder einer anderen ASCII-kompatiblen Codierung speichern. Die Zeichenfolgenliterale in Ihrem Skript haben die Codierung, unter der Sie Ihren Quellcode gespeichert haben.
-
Jede externe Datei, die Sie mit PHP verarbeiten, kann in beliebiger Codierung vorliegen. Wenn PHP es nicht analysieren muss, müssen keine Anforderungen erfüllt werden, um den PHP-Parser bei Laune zu halten.
$foo = file_get_contents('bar.txt');Das obige liest einfach die Bits in
bar.txtin die Variable$foo. PHP versucht nicht, den Inhalt zu interpretieren, zu konvertieren, zu codieren oder anderweitig damit herumzuspielen. Die Datei kann sogar Binärdaten wie ein Bild enthalten, PHP ist das egal. -
Wenn interne und externe Kodierungen übereinstimmen müssen, müssen sie übereinstimmen. Ein häufiger Fall ist die Lokalisierung, woDer Quellcode enthält so etwas wie
echo localize('Foobar')und eine externe Lokalisierungsdatei enthältetwas in der Art:msgid "Foobar"msgstr "フーバー"Beide „Foobar“ -Strings müssen eine identische Bitdarstellung haben, wenn Sie die richtige Lokalisierung finden möchten.Wenn der Quellcode in ASCII gespeichert wurde, die Lokalisierungsdatei jedoch in UTF-16, stimmen die Zeichenfolgen nicht überein.Entweder wäre eine Art Codierungskonvertierung erforderlich oder die Verwendung einer codierungsfähigen String-Matching-Funktion.
Der kluge Leser könnte an dieser Stelle fragen, ob es möglich ist, eine UTF-16-Byte-Sequenz in einem String-Literal einer ASCII-codierten Quellcodedatei zu speichern, auf die die Antwort lauten würde: absolut.
echo "UTF-16";Wenn Sie Ihren Texteditor dazu bringen können, die echo " und "; Teile in ASCII und nur UTF-16 in UTF-16 zu speichern, funktioniert dies einwandfrei. Die dafür notwendige binäre Darstellung sieht folgendermaßen aus:
01100101 01100011 01101000 01101111 00100000 00100010e c h o "11111110 11111111 00000000 01010101 00000000 01010100(UTF-16 marker) U T00000000 01000110 00000000 00101101 00000000 00110001F - 100000000 00110110 00100010 001110116 " ;Die erste Zeile und die letzten beiden Bytes sind ASCII. Der Rest ist UTF-16 mit zwei Bytes pro Zeichen. Das führende 11111110 11111111 in Zeile 2 ist eine Markierung, die am Anfang von UTF-16-codiertem Text erforderlich ist (vom UTF-16-Standard erforderlich, PHP ist das egal). Dieses PHP-Skript gibt gerne die in UTF-16 codierte Zeichenfolge „UTF-16“ aus, da es einfach die Bytes zwischen den beiden doppelten Anführungszeichen ausgibt, die zufällig den in UTF-16 codierten Text „UTF-16“ darstellen. Die Quellcodedatei ist jedoch weder vollständig gültiges ASCII noch UTF-16, sodass die Arbeit damit in einem Texteditor nicht viel Spaß macht.
Fazit
PHP unterstützt Unicode, oder in der Tat jede Codierung, ganz gut, solange bestimmte Anforderungen erfüllt sind, um den Parser glücklich zu machen und der Programmierer weiß, was er tut. Sie müssen wirklich nur vorsichtig sein, wenn Sie Zeichenfolgen bearbeiten, einschließlich Schneiden, Trimmen, Zählen und anderer Vorgänge, die eher auf Zeichenebene als auf Byteebene ausgeführt werden müssen. Wenn Sie mit Ihren Zeichenfolgen neben dem Lesen und Ausgeben nichts „tun“, werden Sie kaum Probleme mit der Unterstützung von Codierungen durch PHP haben, die Sie auch in keiner anderen Sprache hätten.
Codierungsfähige Sprachen
Was bedeutet es dann für eine Sprache, Unicode zu unterstützen? Javascript unterstützt beispielsweise Unicode. Tatsächlich ist jede Zeichenfolge in Javascript UTF-16-codiert. In der Tat ist es das einzige, womit Javascript zu tun hat. Sie können keine Zeichenfolge in Javascript haben, die nicht UTF-16-codiert ist. Javascript verehrt Unicode in dem Maße, dass es keine Möglichkeit gibt, mit einer anderen Codierung in der Kernsprache umzugehen. Da Javascript meistens in einem Browser ausgeführt wird, ist dies kein Problem, da der Browser die alltägliche Logistik der Codierung und Decodierung von Ein- und Ausgabe bewältigen kann.
Andere Sprachen sind einfach codierungsfähig. Intern speichern sie Zeichenfolgen in einer bestimmten Codierung, häufig UTF-16. Im Gegenzug müssen sie informiert werden oder versuchen, die Codierung von allem zu erkennen, was mit Text zu tun hat. Sie müssen wissen, in welcher Codierung der Quellcode gespeichert ist, in welcher Codierung sich eine Datei befindet, in der sie lesen sollen, in welcher Codierung Sie Text ausgeben möchten. und sie konvertieren Codierungen im laufenden Betrieb nach Bedarf mit einer Manifestation von Unicode als Zwischenhändler. Sie tun das Gleiche, was Sie in PHP halbautomatisch hinter den Kulissen tun können / sollten / müssen. Das ist weder besser noch schlechter als PHP, nur anders. Das Schöne daran ist, dass Standardsprachfunktionen, die sich mit Strings befassen, einfach gut funktionieren, während man in PHP darauf achten muss, ob ein String Multibyte-Zeichen enthalten darf oder nicht, und String-Manipulationsfunktionen entsprechend auswählen muss.
Die Tiefen von Unicode
Da Unicode mit vielen verschiedenen Skripten und vielen verschiedenen Problemen zu tun hat, hat es viel Tiefe. Beispielsweise enthält der Unicode-Standard Informationen für Probleme wie die Vereinheitlichung des CJK-Ideogramms. Das heißt, Informationen, dass zwei oder mehr chinesische / japanische / koreanische Zeichen tatsächlich dasselbe Zeichen in leicht unterschiedlichen Schreibmethoden darstellen. Oder Regeln für die Konvertierung von Kleinbuchstaben in Großbuchstaben, umgekehrt und Hin- und Rückfahrt, was in allen Skripten nicht immer so einfach ist wie in den meisten westeuropäischen lateinischen Skripten. Einige Zeichen können auch mit verschiedenen Codepunkten dargestellt werden. Der Buchstabe „ö“ kann beispielsweise mit dem Codepunkt U+00F6 („LATEINISCHER KLEINBUCHSTABE O MIT DIAERESE“) oder als die beiden Codepunkte U+006F („LATEINISCHER KLEINBUCHSTABE O“) und U+0308 („KOMBINIERENDE DIAERESE“) dargestellt werden, also der Buchstabe „o“ kombiniert mit „“. In UTF-8 ist dies entweder die Doppelbyte-Sequenz 11000011 10110110 oder die Dreibyte-Sequenz 01101111 11001100 10001000, die beide dasselbe lesbare Zeichen darstellen. Daher gibt es Regeln für die Normalisierung innerhalb des Unicode-Standards, dh wie eine dieser Formen in die andere konvertiert werden kann. Dies und vieles mehr liegt außerhalb des Geltungsbereichs dieses Artikels, aber man sollte sich dessen bewusst sein.
Final TL;DR
- Text ist immer eine Folge von Bits, die mithilfe von Nachschlagetabellen in lesbaren Text übersetzt werden muss. Wenn die falsche Nachschlagetabelle verwendet wird, wird das falsche Zeichen verwendet.
- Sie haben es nie direkt mit „Zeichen“ oder „Text“ zu tun, Sie haben es immer mit Bits zu tun, die durch mehrere Abstraktionsschichten gesehen werden. Falsche Ergebnisse sind ein Zeichen dafür, dass eine der Abstraktionsebenen fehlschlägt.
- Wenn zwei Systeme miteinander sprechen, müssen sie immer angeben, in welcher Kodierung sie miteinander sprechen möchten. Das einfachste Beispiel dafür ist, dass diese Website Ihrem Browser mitteilt, dass sie in UTF-8 codiert ist.
- In der heutigen Zeit ist die Standardcodierung UTF-8, da sie praktisch jedes Zeichen von Interesse codieren kann, abwärtskompatibel mit dem De-facto-Baseline-ASCII ist und dennoch für die meisten Anwendungsfälle relativ platzsparend ist.
- Andere Codierungen haben gelegentlich noch ihre Verwendung, aber Sie sollten einen konkreten Grund haben, sich mit den Kopfschmerzen zu befassen, die mit Zeichensätzen verbunden sind, die nur eine Teilmenge von Unicode codieren können.
- Die Zeiten von einem Byte = einem Zeichen sind vorbei und sowohl Programmierer als auch Programme müssen dies nachholen.
Jetzt sollten Sie wirklich keine Entschuldigung mehr haben, wenn Sie das nächste Mal Text verstümmeln.
-
Ja, das bedeutet, dass ASCII mit nur 7 Bit gespeichert und übertragen werden kann, und das ist es oft. Nein, dies liegt nicht im Rahmen dieses Artikels und aus Gründen der Argumentation gehen wir davon aus, dass das höchste Bit in ASCII „verschwendet“ wird. ↩
-
Und wenn nicht, wird es erweitert. Es war schon mehrmals. ↩
-
Bitte beachten Sie, dass wenn ich den Begriff „Start“ zusammen mit „Byte“ verwende, ich es aus der Sicht des Menschen lesbar meine. ↩
-
Lesen Sie die UTF-8-Spezifikation, wenn Sie dies mit Stift und Papier verfolgen möchten. ↩
-
Hey, ich bin Programmierer, kein Biologe. ↩
-
Und natürlich wird es kein aktuelles Backup geben. ↩
-
Ein „Unicode-Zeichen“ ist ein Codepunkt in der Unicode-Tabelle. „あ“ ist kein Unicode-Zeichen, sondern der Hiragana-Buchstabe あ. Es gibt einen Unicode-Codepunkt dafür, aber das macht den Buchstaben selbst nicht zu einem Unicode-Zeichen. Ein „UTF-8-Zeichen“ ist ein Oxymoron, kann aber gedehnt werden, um zu bedeuten, was technisch eine „UTF-8-Sequenz“ genannt wird, die eine Bytesequenz von einem, zwei, drei oder vier Bytes ist, die ein Unicode-Zeichen darstellen. Beide Begriffe werden oft im Sinne von „jeder Buchstabe, der nicht Teil meiner Tastatur ist“ verwendet, was absolut nichts bedeutet. ↩
-
http://www.php.net/manual/en/function.utf8-encode.php ↩
Über den Autor
David C. Zentgraf ist ein Webentwickler, der teilweise in Japan und Europa arbeitet und regelmäßig an Stack Overflow arbeitet.Wenn Sie Feedback, Kritik oder Ergänzungen haben, können Sie @deceze auf Twitter ausprobieren, seine E-Mail-Adresse erraten oder mit altehrwürdigen Methoden nachschlagen.Dieser Artikel wurde veröffentlicht am kunststube.net . Und nein, es gibt kein Schimpfwort in „Kunststube“.